Deep Learning을 공부하고자 하는 많은 입문자들을 위하여 내가 공부하면서 입문서로 가장 도움이 되었던 Michael Nielsen의 온라인 도서를 여기 장별로 정리하여 두고자 한다.
이 장에서 나오는 내용들은 그의 온라인 도서 3장에 대한 내용을 한국어로 얼기설기 번역한 것이다. 번역이 어색하지만, 개념을 이해하기에는 무리가 없다고 생각한다.
골프 선수가 처음 골프를 배울 때는 대부분 기본 스윙을 익히는데 시간을 보냅니다. 하지만 점차 다른 샷을 익히고, 칩샷, 드로우샷, 페이드샷을 배우며 기본 스윙을 발전시키고 수정해 나갑니다. 마찬가지로 지금까지는 역전파 알고리즘을 이해하는데 집중했습니다. 이는 대부분의 신경망 학습에서 학습의 기반이 되는 "기본 스윙"입니다. 이 장에서는 기존의 역전파 알고리즘 구현을 개선하고 신경망의 학습 방식을 개선하는 데 사용할 수 있는 여러가지 기법을 설명합니다.
이 장에서 개발할 기법은 다음과 같습니다.
- 교차 엔트로피 비용 함수(cross-entropy cost function)이라고 알려진 더 나은 비용함수
- 네 가지의 "정규화"(regularization) 방법 (L1과 L2 정규화, 드롭아웃(dropout), 그리고 학습 데이터의 인위적 확장, 이들은 신경망이 학습 데이터의 범위를 넘어서 일반화하는데 더 효과적이도록 합니다.)
- 신경망에 적합한 하이퍼파라미터를 선택하는데 도움이 되는 일련의 휴리스틱
- 기타 몇 가지 다른 기법들
위의 논의들은 대체로 독립적이므로 원하는 주제로 바로 넘어가도 무방합니다. 또한, 이 기법들 중 다수를 실행코드로 구현하고, 이를 사용하여 1장에서 다룬 필기 분류 문제에서 얻은 결과를 개선해보는 것도 진행할 계획입니다.
물론, 여기서는 신경망에 사용하기 위해 개발된 수많은 기술 중 일부만 다루고 있습니다. 수많은 기술 중 가장 중요한 몇가지를 심도 있게 연구하는 것이야 말로 이 책의 핵심 철학입니다. 이러한 중요한 기술을 숙달하는 것은 그 자체로 유용할 뿐만 아니라, 신경망을 사용할 때 발생할 수 있는 문제에 대한 이해도 깊어집니다. 이를 통해 필요에 따라 다른 기술들을 빠르게 습득할 수 있는 준비를 갖추게 됩니다.
교차 엔트로피 비용 함수
대부분의 사람들은 틀리는 것을 불쾌하게 생각합니다. 피아노를 배우기 시작한지 얼마되지 않아 청중 앞에 첫 연주를 했습니다. 긴장한 나머지 한 옥타브 낮게 연주하기 시작했습니다. 헷갈려서 누군가 제 실수를 지적해줄 때까지 계속해서 연주할 수 밖에 없었습니다. 정말 당황스러웠습니다. 하지만 불쾌할 수도 있지만, 결정적으로 틀렸을 때는 금방 배우게 됩니다. 다음 번에 청중 앞에서 연주했을 때는 분명 정확한 옥타브로 연주했을 겁니다. 반대로, 실수가 명확하게 정의되지 않았을 때는 더 느리게 배우게 됩니다.
이상적으로 신경망이 오류로 부터 빠르게 학습하기를 기대하고 기대합니다. 실제로도 그럴까요? 이 질문에 답하기 위해 간단한 예를 살펴보겠습니다. 입력이 하나뿐인 뉴런이 있다고 가정하겠습니다.

우리는 이 뉴런을 엄청나게 쉬운 일, 즉 1을 입력받아 0을 출력하는 일을 하도록 학습시킬 것입니다. 이는 매우 간단한 작업으로 학습 알고리즘을 사용하지 않고도 적절한 가중치와 편향을 직접 계산할 수 있습니다. 하지만 경사 하강법을 사용하여 가중치와 편향을 학습하도록 해보겠습니다. 자, 이제 뉴런이 어떻게 학습하는지 살펴보겠습니다.
초기 가중치를 0.6, 그리고 초기 편향을 0.9로 선택해보도록 하겠습니다. 이들은 특별한 값이 아니라 그냥 마음대로 선택한 값들입니다. 뉴런의 초기 출력은 0.82라고 해보겠습니다. 따라서, 뉴런이 우리가 원하는 출력인 0.0에 가까워지기 위해서는 상당한 학습이 필요할 것입니다. 아래 그림의 오른쪽 하단 모서리에 있는 "Run" 버튼을 클릭하면 뉴런이 출력을 0.0에 가깝도록 학습하는지 알수 있을 것입니다. 아래 그림은 녹화된 애니메이션이 아닙니다. 브라우저가 실제로 기울기를 계산한 다음 이 기울기를 사용하여 가중치와 편향을 갱신한다음 결과를 표시하는 자바스크립트로 된 프로그램의 실제 실행 결과입니다. 이 프로그램은 학습율 $\eta = 0.15$로 설정되어 사람 눈으로도 무슨 일이 일어나고 있는지 볼 수 있을만큼 느리지만, 단 몇초만에 상당한 학습을 얻을 수 있을 만큼 빠릅니다. 비용으로는 1장에서 소개한 이차 비용함수 $C$를 사용했습니다. 이 비용함수의 정확한 형태는 곧 소개하도록 하겠습니다. "Run" 버튼을 다시 클릭하여 여러번 반복 실행할 수 있습니다.
보시다시피 뉴런은 비용을 낮추는 가중치와 편향을 빠르게 학습하고 약 0.09의 출력을 산출합니다. 이는 우리가 원하는 출력 0.0은 아니지만, 꽤나 근접한 출력입니다. 위에서는 초기 가중치를 0.6과 초기 편향을 0.9로 선택했습니다. 하지만 이번에는 초기 가중치와 편향을 모두 2.0으로 선택한다고 가정해보겠습니다. 이 경우 초기 출력은 0.98이 됩니다. 이는 우리가 원하는 출력과 상당히 차이가 나는 값입니다. 자, 이 경우 뉴런이 어떻게 출력을 0으로 산출하는 법을 배우는지 봅시다. 아래 그림의 "Run"을 다시 한번 눌러봅시다.
위에서도 동일한 학습율($\eta = 0.15$)를 사용하지만 학습이 훨씬 더 느리게 시작됨을 알 수 있습니다. 실제로 처음 150회 정도의 학습 에포크 동안에는 가중치와 편향이 거의 변하지 않습니다. 그런 다음 학습이 시작되고, 첫번째와 마찬가지로 뉴런의 출력은 빠르게 0.0에 가까워집니다.
이러한 행동은 인간의 학습과 비교했을 때 이상합니다. 이 섹션에서 서두에 말씀드렸듯이, 우리는 종종 무언가에 대해 크게 틀렸을 때 가장 빨리 학습합니다. 하지만 방금 인공 뉴런이 크게 틀렸을 때 학습하는데 많은 어려움을 겪는다는 것을 확인했습니다. 약간 틀렸을 때보다 훨씬 더 어렵습니다. 게다가, 이러한 행동은 이 시험용 신경망 모델뿐만 아니라 더 일반적인 신경망에서도 발생한다는 것이 밝혀졌습니다. 왜 학습속도가 이렇게 느릴까요? 그리고 이러한 속도저하를 피할 방법을 찾을 수 있을까요?
문제의 근원을 이해하기 위해서 우리 뉴런은 비용 함수의 편미분($\partial C / \partial w$와 $\partial C / \partial b$)에 의해 결정되는 비율로 가중치와 편향을 변경하여 학습한다는 것을 다시 한번 상기해보시기 바랍니다. 따라서 "학습이 느리다"라는 말은 이 편미분한 값이 작다는 것을 의미합니다. 문제는 이 편미분 값이 왜 작은지 이해하는 것입니다. 이를 이해하기 위해 편미분을 계산해보겠습니다. 우리가 이차 비용 함수를 사용하고 있다는 점을 다시 한번 기억하시기 바랍니다. 식 (6)에 따르면 이 함수는 다음과 같습니다. (학습용 입력값으로 $X = 0$가 주어졌을 때, 우리가 바라는 출력은 $y = 0$이며, $a$는 뉴런의 출력값입니다.)
$\begin{eqnarray} C = \frac{(y-a)^2}{2},\tag{54}\end{eqnarray}$
위 식을 가중치와 편향의 관점에서 더 명확하게 작성하기 위하여, $z = wx + b$일 때, $a = \sigma (z)$임을 다시 한번 기억하시기 바랍니다. 가중치와 편향에 대하여 합성함수 미분법을 사용하여 미분하면 다음 식들을 얻을 수 있습니다. ($x = 1$과 $y = 0$을 대입했습니다.)
$\begin{eqnarray} \frac{\partial C}{\partial w} & = & (a-y)\sigma'(z) x = a \sigma'(z) \tag{55}\\ \frac{\partial C}{\partial b} & = & (a-y)\sigma'(z) = a \sigma'(z),\tag{56}\end{eqnarray}$
이 식의 동작을 이해하기 위하여, 우항의 $\sigma '(z)$를 좀 더 자세히 살펴보도록 하겠습니다. 그리고 함수 $\sigma$의 모양은 아래와 같음을 다시 한번 기억해보시길 바랍니다.

교차 엔트로피 비용 함수(The cross-entropy cost function) 소개
학습 속도 저하를 어떻게 해결할 수 있을까요? 이차 비용 함수를 교차 엔트로피라는 다른 비용 함수로 대체하면 문제를 해결할 수 있습니다. 교차 엔트로피를 이해하기 위해 조금 다른 시험용 신경망을 예를 들어보겠습니다. 여러 개의 입력 $x_1, x_2, ...$에 대하여 각각 가중치 $w_1, w_2, ...$와 편향 $b$를 갖는 뉴런을 학습시킨다고 가정해봅시다.

$\begin{eqnarray} C = -\frac{1}{n} \sum_x \left[y \ln a + (1-y ) \ln (1-a) \right],\tag{57}\end{eqnarray}$
식 (57)로 학습 속도 저하 문제를 해결할 수 있는지는 아직 명확하지 않습니다. 사실, 솔직히 말해서, 이를 비용 함수로 부르는 것조차 의미가 있는지 조차 명확하지 않습니다. 학습 속도 저하 문제를 다루기 전에 교차 엔트로피가 어떤 의미에서 비용 함수로 해석될 수 있는지 부터 살펴보겠습니다.
특히 두가지 속성 때문에 교차 엔트로피를 비용 함수로 해석하는 것을 합리적으로 볼 수 있습니다. 첫째, $C > 0$으로 교차 엔트로피가 음수가 아닙니다. 이것을 이해하려면 다음 사항들을 주목하세요: (a) 식 (57)에서 합산을 하는 모든 개별 항들은 음수입니다. 두 로그함수의 입력 값이 모두 0과 1사이의 수이기 때문입니다. (b) 그리고 합산의 앞에 마이너스 부호가 있습니다. 따라서, 전체 값은 음수가 아닙니다.
둘째, 뉴런의 실제 출력이 모든 학습 데이터 $x$에 대하여 원하는 출력에 가깝다면 교차 엔트로피는 0에 가까워집니다. 이를 이해하기 위해서 예를 들어 어떤 입력 $x$에 대하여 $y = 0$이고, $a \approx 0$이라고 가정해봅시다. 이 경우 뉴런이 해당 입력에 대해 잘 작동하고 있다는 의미입니다. 비용 함수 식에서 첫번째 항은 $y = 0$이므로 사라지고 두번째 항 $-ln(1 - a) \approx 0$이 됩니다. $y = 1$이고 $a \approx 0$일 때도 비슷하게 적용됩니다. 따라서 실제 출력이 원하는 출력에 가까우면 비용에 대한 기여도가 낮아집니다.
요약하면 교차 엔트로피는 양수이며 뉴런이 모든 학습 데이터 $x$에 대해 원하는 출력 $y$에 가까운 출력값을 더 잘 계산할수록 0에 가까워집니다. 이 두 가지 속성은 비용 함수에 대해 우리가 직관적으로 기대하는 특성입니다. 실제로 이 두가지 속성은 이차 비용 함수에서도 만족됩니다. 따라서 이는 교차 엔트로피에도 좋은 소식입니다.
하지만, 교차 엔트로피 비용 함수는 2차 비용 함수와 달리 학습 속도 저하 문제를 피할 수 있다는 장점이 있습니다. 이를 확인하기 위해 가중에 대한 교차 엔트로피 비용의 편미분을 계산해 보겠습니다. $a = \sigma (z)$를 식 (57)에 대입하고 합성함수 편미분법을 다음과 같이 두 번 적용해 보겠습니다.
$\begin{eqnarray} \frac{\partial C}{\partial w_j} & = & -\frac{1}{n} \sum_x \left( \frac{y }{\sigma(z)} -\frac{(1-y)}{1-\sigma(z)} \right) \frac{\partial \sigma}{\partial w_j} \tag{58}\\ & = & -\frac{1}{n} \sum_x \left( \frac{y}{\sigma()} -\frac{(1-y)}{1-\sigma(z)} \right)\sigma'(z) x_j.\tag{59}\end{eqnarray}$
모든 것을 공통분모로 놓고 간단히 정리하면 다음과 같습니다.
$\begin{eqnarray} \frac{\partial C}{\partial w_j} & = & \frac{1}{n} \sum_x \frac{\sigma'(z) x_j}{\sigma(z) (1-\sigma(z))} (\sigma(z)-y).\tag{60}\end{eqnarray}$
시그모이드 함수 $\sigma (z) = 1 / (1 + e^{-z})$의 정의와 약간 대수학을 사용하면 $\sigma'(z) = \sigma(z)(1 - \sigma(z))$임을 보일 수 있습니다. 이를 위 식에 대입하면 $\sigma'(z)$항과 $\sigma(z)(1 - \sigma(z))$항이 상쇄되어 다음과 같이 간단해집니다.
$\begin{eqnarray} \frac{\partial C}{\partial w_j} = \frac{1}{n} \sum_x x_j(\sigma(z)-y).\tag{61}\end{eqnarray}$
이 식은 정말 아름답습니다. 이 식은 가중치가 학습되는 속도가 $\sigma(z) - y$, 즉 출력 오차에 의해 결정된다는 것을 알려줍니다. 오차가 클수록 뉴런은 더 빠르게 학습합니다. 이는 우리가 직관적으로 기대하는 바와 정확히 일치합니다.
특히, 이 식은 2차 비용 함수의 유사한 방정식인 식 (55)에서 $\sigma'(z)$항으로 인해 발생한 학습 속도 저하 문제를 피할 수 있습니다. 교차 엔트로피를 사용하면 $\sigma'(z)$항이 상쇄되어 더 이상 이 항이 작아지는 것에 대해 걱정할 필요가 없습니다. 이러한 상쇄는 교차 엔트로피 비용 함수가 가져다주는 특별한 '기적'입니다. 사실 이것은 진정한 기적이 아닙니다 나중에 보겠지만 교차 엔트로피는 정확히 이러한 속성을 갖도록 특별히 선택된 것입니다.
비슷한 방식으로 편향에 대한 편미분도 계산할 수 있습니다. 세부 사항은 다시 다루지 않겠지만, 다음을 쉽게 확인할 수 있습니다.
$\begin{eqnarray} \frac{\partial C}{\partial b} = \frac{1}{n} \sum_x (\sigma(z)-y).\tag{62}\end{eqnarray}$
다시 말해, 이것은 이차 비용 함수의 유사한 방정식인 식 (56)에서 $\sigma'(z)$ 항으로 인하여 발생했던 학습 속도 저하를 방지합니다.
앞서 다루었던 간단한 예로 돌아가서 이차 비용 함수대신 교차 엔트로피를 사용하면 어떤 일이 일어나는지 살펴보겠습니다. 다시 한번, 이차 비용 함수가 초기 가중치 0.6와 초기 편향 0.9를 사용하여 잘 동작했던 경우부터 시작해보겠습니다. 아래 그림의 "Run"을 눌러 이차 비용 함수를 교차 엔트리피로 바꾸면 어떤 일이 일어나는지 확인해보시기 바랍니다.
지금까지 우리가 살펴보았던 것처럼, 이 경우에도 뉴런은 이전과 마찬가지로 완벽에 가깝게 학습합니다. 이제 이전에 뉴런이 잘 학습하지 못했던 초기 가중치와 초기 편향을 모두 2.0으로 설정했던 경우를 살펴보겠습니다.
성공! 이번에는 뉴런이 우리가 기대했던 대로 빠르게 학습함을 알 수 있습니다. 자세히 살펴보면 비용 곡선의 기울기가 이차 비용 곡선의 초기 평탄 영역보다 훨씬 가파르다는 것을 알 수 있습니다. 바로 이러한 가파른 기울기 덕분에 교차 엔트로피는 뉴런이 가장 빨리 학습할 것으로 예상했던 시점, 즉 뉴런이 처음부터 매우 잘못된 학습을 했을 때 학습이 중단되는 것을 방지합니다.
방금 설명한 예시들에서 어떤 학습율을 사용했는지를 언급하지 않았습니다. 이전에 이차 비용 함수를 사용했을 때는 $\eta = 0.15$를 썼습니다. 이번의 예시에서도 같은 학습율을 사용했을까요? 사실, 비용 함수가 바뀌었기 때문에 "같은" 학습율을 사용한다는 것이 정확히 무엇을 의미하는지 말하기 어렵습니다. 사과와 오렌지를 비교하는 것과 같습니다. 두 비용 함수 모두에 대해 제가 단순히 실험을 통해 상황을 잘 보여줄 수 있는 학습율을 찾아서 썼습니다. 혹시 궁금해할 수도 있어서, 말씀드리자면 이번 예시들에서 사용한 학습율은 $\eta = 0.005$입니다.
이와 같이 다른 학습율을 적용하는 것이 위의 그래프를 무의미하게 만든다고 반박할 수도 있습니다. 학습율 선택 자체가 처음부터 임의적이었는데, 뉴런이 얼마나 빠르게 학습하는지가 왜 중요하냐고요? 그런 반박은 요점을 놓치고 있습니다. 그래프의 요점은 학습의 절대적인 속도에 관한 것이 아닙니다. 학습 속도가 어떻게 변하는지에 관한 것입니다. 특히, 이차 비용 함수를 사용할 때는 명백히 틀렸을 때 학습이 더 느렸고, 뉴런이 올바른 출력에 가까워질수록 빨라졌습니다. 반면, 교차 엔트로피를 사용하면 뉴런이 명백히 틀렸을 때 학습이 더 빠릅니다. 이러한 진술은 학습율이 어떻게 설정되었는지와 크게 상관이 없습니다.
지금까지 우리는 단일 뉴런에 대한 교차 엔트로피를 살펴보았습니다. 이를 교차 엔트로피를 다중 뉴런 다층 네트워크로 일반화하는 것도 어렵지 않습니다. 특히, 출력 뉴런 즉 최종 계층에서 뉴런에서 원하는 값이 $y = y_1, y_2, ...$이고 실제 출력 값이 $a^L_1, a^L_2, ...$라고 가정해 봅시다. 그러면 교차 엔트로피는 다음과 같이 정의됩니다.
$\begin{eqnarray} C = -\frac{1}{n} \sum_x \sum_j \left[y_j \ln a^L_j + (1-y_j) \ln (1-a^L_j) \right].\tag{63}\end{eqnarray}$
이것은 앞서 다룬 식 (57)과 동일하지만, 이제 모든 출력 뉴런에 대하여 $\sum_j$로 합산한다는 점이 다릅니다. 제가 따로 이 식에 대한 유도를 자세히 다루지는 않겠지만, 식 (63)을 사용하면 다중 뉴런 네트워크에서 학습 속도 저하를 피할 수 있다는 것은 충분히 설득력이 있을 것입니다.
덧붙여 저는 "교차 엔트로피"라는 용어를 일부 초기 독자들이 혼란스러울 수 있도록 사용하고 있습니다. 다른 분야에서와 표면적으로 충돌하는 것처럼 보일 수도 있습니다. 특히, 두 확율분포 $p_j$와 $q_j$에 대한 교차 엔트로피를 $\sum_jp_jlnq_j$로 정의하는 것이 일반적입니다. 이 정의는 단일 시그모이드 뉴런이 뉴런의 활성화 $a$와 그 보수 $1 - a$로 구성된 확율 분포를 출력하는 것으로 간주한다면 식 (51)도 교차 엔트로피와 유사합니다.
그러나 최종 계층이 여러 개의 시그모이드 뉴런이 있을 때, 활성화 벡터 $a^L_j$는 일반적으로 확률 분포를 형성하지 않습니다. 결과적으로 우리가 확률 분포를 다루는 것이 아니기 때문에 $\sum_jp_jlnq_j$와 같은 정의는 의미가 없습니다. 대신, 식 (63)을 각 뉴런의 활성화를 두 요소 확율 분포의 일부로 해석하여, 뉴런별 교차 엔트로피의 합으로 생각할 수는 있습니다. 물론, 우리 신경망에서 확률적 요소가 없으므로 실제 확률은 아닙니다. 이러한 의미에서 식 (63)은 확률 분포에 대한 교차 엔트로피의 일반화입니다.
그러면, 언제 이차 비용 함수 대신 교차 엔트로피를 사용해야할까요? 사실, 출력 뉴런이 시그모이드 뉴런인 경우 교차 엔트로피가 거의 항상 훨씬 더 나은 선택입니다. 그 이유를 알아보겠습니다.
신경망을 설정할 때, 우리는 보통 가중치와 편향을 무작위로 초기화합니다. 이러한 초기 선택으로 인해 일부 학습 데이터에 대하여 신경망이 결정적으로 잘못될 수 있습니다. 즉, 뉴런 출력이 0이 되어야할 때, 1 근처에서 포화되거나 그 반대가 될 수 있습니다. 만약 이러한 때 이차 비용을 사용한다면 학습 속도가 늦어지게 될 것입니다. 완전히 학습을 멈추지는 않겠지만 다른 학습 데이터로부터 계속 학습하더라도 분명히 바람직하지 않습니다.
교차 엔트로피를 사용한 MNIST 숫자 분류
우리가 앞 장에서 살펴본 프로그램을 교차 엔트로피를 사용하도록 쉽게 다시 구현할 수 있습니다. 이 장의 후반부에서 MNIST 손글씨 숫자 분류를 위한 이전 프로그램(network.py)을 개선하여 새 프로그램(network2.py)을 만들어 보겠습니다. 개선할 때, 교차 엔트로피 뿐만 아니라 이 장에서 다룬 여러 다른 기법들도 통합해보도록 하겠습니다. 지금은 새로운 프로그램이 MNIST 숫자를 얼마나 잘 분류하는지 살펴보겠습니다. 1장에서와 마찬가지로 은닉 뉴런은 30개, 미니 배치의 크기는 10으로 설정하도록 하겠습니다. 그리고 학습율 $\eta = 0.5$로 에포크는 30으로 하여 학습을 하도록 하겠습니다. 개새롭게 개선된 network2.py의 인터페이스는 network.py와 약간 다르지만 어떻게 작동하는지는 여전히 동일합니다. 참고로, python shell에서 help(network2.Network.SDG)와 같이 명령을 입력하면 network2.py의 인터페이스에 대한 문서를 볼 수 있습니다.
>>> import mnist_loader >>> training_data, validation_data, test_data = \ ... mnist_loader.load_data_wrapper() >>> import network2 >>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost) >>> net.large_weight_initializer() >>> net.SGD(training_data, 30, 10, 0.5, evaluation_data=test_data, ... monitor_evaluation_accuracy=True)
* 주석: 교차 엔트로피를 사용한 network2.py와 run2.py는 이 링크에서 받을 수 있다. (python 3.13 환경에서 구동 가능)
참고로 net.large_weight_initializer() 명령은 1장에서 사용한 것과 같은 방식으로 가중치와 편향을 초기화하는데 사용됩니다. 이 장의 둣부분에서 네트워크의 기본 가중치 초기화 부분을 변경할 것이기 때문에, 지금은 이 명령을 사용해야합니다. 위 명령들을 순서대로 실행하면 95.49%의 정확도를 갖는 신경망이 생성됩니다. 이는 1장에서 이차 비용을 사용하여 얻은 결과(95.42% 정확도)와 매우 유사합니다.
또한, 교차 엔트리피를 사용하여 다른 매개변수는 동일하게 유지하되 100개의 은닉 뉴런을 갖도록 신경망을 수정했을 때를 살펴보겠습니다. 이 경우 96.82%의 정확도를 갖는 결과를 얻을 수 있습니다. 이는 이차 비용 함수를 사용하여 96.59%의 분류 정확도를 얻었던 1장의 결과에 비해 상당히 개선된 것입니다. 작은 변화처럼 보일 수 있지만, 오류율이 3.41%에서 3.18%로 감소했다는 점을 고려해보세요. 즉 원래 오류 중 약 14개 중 1개를 제거한 것입니다. 이는 꽤 유용한 개선입니다.
교차 엔트로피 비용 함수가 이차 비용 함수보다 유사하거나 더 나은 결과를 제공한다는 점은 고무적입니다. 하지만 이러한 결과가 교차 엔트로피가 더 나은 선택임을 결정적으로 증명하는 것은 아닙니다. 그 이유는 제가 학습률, 미니 배치 크기 등과 같은 하이퍼파라미터를 선택하는 데 약간의 노력만 들였기 때문입니다. 개선사항들이 정말 설득력을 얻으려면 그러한 하이퍼파라미터를 최적화하는데 철저한 노력을 기울여야 합니다.
그럼에도 불구하고 결과는 고무적이며 교차 엔트로피가 이차 비용보다 더 나은 선택이라는 이전의 이론적 주장을 강화합니다.
이것은 이 장과 이 책의 나머지 많은 부분에서 보게될 일반적인 패턴의 일부입니다. 우리는 새로운 기술을 개발하고 시도해보고 "개선된" 결과를 얻을 것입니다. 물론 이러한 개선을 보는 것은 좋은 일입니다. 하지만 그러한 개선에 대한 해석은 항상 문제가 됩니다. 모든 다른 하이퍼파라미터를 최적화하는데 엄청난 노력을 기울인 후에 개선을 확인해야만 진정으로 설득력이 있습니다. 이는 많은 컴퓨텅 성능을 필요로 하는 엄청난 작업이며 우리는 일반적으로 그렇게 철저한 조사를 하지 않을 것입니다. 대신, 위에서 수행된 것과 같은 비공식적 테스트를 기반으로 진행할 것입니다. 하지만 그러한 테스트가 결정적인 증명에는 미치지 못한다는 점을 명심하고 항상 주의를 기울여야 합니다.
지금까지 교차 엔트로피에 대해서 길게 논의했습니다. MNIST 결과에 약간의 개선만 주는데 왜 그렇게 많은 노력을 기울였을까요? 이 장의 뒷부분에서 훨씬 더 큰 개선을 제공하는 다른 기술, 특히 정규화를 보게될 것입니다. 그렇다면 우리는 왜 교차 엔트로피를 이해하기 위하여 이렇게 많은 논의를 했을까요? 부분적으로는 교차 엔트로피가 널리 사용되는 비용 함수이므로 잘 이해할 가치가 있기 때문입니다. 하지만 더 중요한 이유는 뉴런 표화(neuron saturation)가 신경망에서 중요한 문제이며, 이 책 전반에 결처 반복적으로 다룰 문제이기 때문입니다. 따라서 저는 뉴런 포화와 이를 해결하는 방법을 이해하기 위해 좋은 예시이기 때문에 교차 엔트로피를 길게 설명했습니다.
교차 엔트로피의 의미와 유래
교차 엔트로피에 대한 우리의 논의는 대수적 분석과 실제 구현에 중점을 두었습니다. 이는 유용하지만 교차 엔트로피의 실제 무엇을 의미하는지, 이에 대해 직관적으로 생각할 방법은 있는지, 그리고 우리는 교차 엔트로피를 어떻게 처음 생각해 낼 수 있었는지와 같은 더 넓은 개념적 질문들은 여전히 남아있습니다.
이러한 질문들 중 마지막 질문부터 시작해보겠습니다. 우리가 교차 엔트로피를 처음으로 생각하게 된 동기는 무엇이었을까요? 만약 우리가 앞에서 설명한 학습 속도 저하를 발견했고, 그 원인이 식 (55)와 (56)의 $\sigma '(z)$항에 있다는 것을 이해했다고 가정해봅시다. 그 식을 잠시 동안 응시한 후 우리는 $\sigma '(z)$항이 사라지도록 비용 함수를 선택하는 것이 가능할지 궁금해할 수 있습니다. 그런 경우, 하나의 학습 데이터 $x$에 대한 비용 $C = C(x)$는 다음을 만족할 것입니다.
$\begin{eqnarray} \frac{\partial C}{\partial w_j} & = & x_j(a-y) \tag{71}\\ \frac{\partial C}{\partial b } & = & (a-y).\tag{72}\end{eqnarray}$
이 식들을 참으로 만드는 비용 함수를 선택할 수 있다면, 초기 오차가 클수록 뉴런의 학습속도가 빨라진다는 것을 직관적으로 알 수 있습니다. 이로써 우리는 학습 속도 저하 문제를 해결할 수 있을 것입니다. 실제로, 이 식들을 바탕으로 수학적 원리를 따라가기만 하면 교차 엔트로피의 형태를 도출할 수 있음음을 지금부터 살펴보도록 하겠습니다. 이를 확인하기 위해서 합성합수 미분법으로 부터 다음과 같은 식이 성립한다는 점을 먼저 유의하시기 바랍니다.
$\begin{eqnarray} \frac{\partial C}{\partial b} = \frac{\partial C}{\partial a} \sigma'(z).\tag{73}\end{eqnarray}$
$$\sigma'(z) = \sigma(z)(1-\sigma(z)) = a(1-a)$$을 위 식에 대입하면 다음과 같은 식을 얻을 수 있습니다.
$\begin{eqnarray} \frac{\partial C}{\partial b} = \frac{\partial C}{\partial a} a(1-a).\tag{74}\end{eqnarray}$
이를 식 (72)와 비교하면, 우리는 다음의 식을 얻을 수 있습니다.
$\begin{eqnarray} \frac{\partial C}{\partial a} = \frac{a-y}{a(1-a)}.\tag{75}\end{eqnarray}$
이 식을 $a$에 대하여 적분하면 다음과 같은 결과를 얻습니다.
$\begin{eqnarray} C = -[y \ln a + (1-y) \ln (1-a)]+ {\rm constant},\tag{76}\end{eqnarray}$
여기서 상수는 적분 상수입니다. 이것은 하나의 학습 데이터 $x$의 비용 기여도입니다 전체 비용 함수를 얻으려면 모든 학습 데이터에 대한 평균을 계산해야 하며, 이는 다음의 식으로 가능합니다. (여기서 상수(constant)는 각 학습 데이터에 대한 개별 상수의 평균입니다.)
$\begin{eqnarray} C = -\frac{1}{n} \sum_x [y \ln a +(1-y) \ln(1-a)] + {\rm constant},\tag{77}\end{eqnarray}$
따라서 우리는 식 (71)과 (72)에서 전체 상수항(constant)까지 교차 엔트로피의 형태를 고유하게 결정한다는 것을 알 수 있습니다. 교차 엔트로피는 무에서 갑자기 창조된 것이 아닙니다. 오히려 간단하고 자연스러운 방식으로 발견된 것입니다.
교차 엔트로피의 직관적인 의미는 무엇일까요? 우리는 이것을 어떻게 생각해야할까요? 이것을 깊이있게 다루기 위해서는 많은 설명이 필요할지도 모릅니다. 그러나 정보 이론 분야에서 나오는 교차 엔트로피를 해석하는 표준적인 방법이 있다는 점은 언급할 가치가 있습니다. 대락적으로 말해서, 교차 엔트로피는 놀람의 척도 정도로 이해될 수 있습니다. 우리의 뉴런은 함수 $x \rightarrow y = y(x)$를 계산하고자 하지만, 그 대신으로 함수 $x \rightarrow a = a(x)$를 계산합니다. $a$를 $y$가 1일 확률에 대한 우리 뉴런의 추정치라고 생각하고, $1-a$를 $y$에 대한 올바른 값이 0일 확률에 대한 추정치라고 생각합니다. 그러면, 교차 엔트로피는 $y$에 대한 실제 값을 알게되었을 때 우리가 평균적으로 얼마나 "놀라는지"에 대한 측정입니다. 출력이 예상하는 것과 같으면 놀람이 적고 출력이 예상치 못한 것이면 놀람이 큽니다. 물론, 제가 정확히 "놀람"이 무엇을 의미하는지 말하지 않았기 때문에 이것은 아마도 공허한 말처럼 보일 것입니다. 그러나 사실 놀람이 무엇을 의미하는지에 대한 정확한 정보 이론적 방식이 있습니다. 이 주제에 대하여 더 깊이 있게 알고 싶다면 위키백과의 내용을 참고하시기 바랍니다. 더 깊이 있는 이해를 필요로 하신다면, Cover and Thomas의 책의 5장을 참고하시기 바랍니다.
소프트맥스(Softmax)
이 장에서는 주로 학습 속도 저하 문제를 해결하기 위하여 교차 엔트로피 비용 함수를 사용할 것입니다. 하지만, 여기서 소위 소프트맥스(softmax) 계층의 뉴런에 기반한 문제에 대한 또 다른 접근 방식을 간략하게 설명하고자 합니다. 이번 장의 나머지 부분에서는 실제로 소프트맥스 계층을 사용하지 않을 것이므로, 관심이 없으신 분들은 다음 섹션을 건너뛰셔도 됩니다. 하지만, 소프트맥스는 그 자체로 흐미롭고 6장에서 심층 신경망에 대해 논의할 때, 소프트맥스를 사용할 것이기 때무넹 이해할 가치가 있습니다.
소프트맥스에 대한 기본 아이디어는 우리 신경망에 대한 새로운 유형의 출력 계층을 정의하는 것입니다. 이는 시그모이드 계층과 마찬가지로 가중 입력 $z^L_j = \sum_{k} w^L_{jk} a^{L-1}_k + b^L_j$를 형성하는 것으로 시작합니다. 그러나 출력을 얻기 위해 시그모이드 합수를 적용하지 않습니다. 대신 소프트맥스 계층에서는 $z^L_j$에 소위 소프트맥스 함수를 적용합니다. 이 함수에 따르면 $j$번째 출력 뉴런의 활성화 값 $a^L_j$는 다음과 같습니다. (분모에서 모든 출력 뉴런에 대한 합계를 계산합니다.)
$\begin{eqnarray} a^L_j = \frac{e^{z^L_j}}{\sum_k e^{z^L_k}},\tag{78}\end{eqnarray}$
소프트맥스 함수에 대해 익숙하지 않는다면 식 (78)이 꽤나 난해해 보일 수 있습니다. 우리가 이 함수를 사용해야하는 이유도 명확하지 않으며, 학습 속도 저하 문제를 해결하는데 도움이 될 것이라는 점도 분명하지 않습니다. 식 (78)을 더 잘 이해하기 위해서 4개의 출력 뉴런과 그에 해당하는 4개의 가중 입력이 있는 신경망이 있다고 가정해보겠습니다. 이 가중 입력을 각각 $z^L_1, z^L_2, z^L_3, z^L_4$라고 표시하겠습니다. 아래에 가능한 가중 입력값을 보여주는 조절 가능한 슬라이더와 해당 출력 활성화 그래프가 나와 있습니다. 맨 아래에 있는 $z^L_4$의 슬라이더를 이동시켜보며 그 변화를 체감해보시기 바랍니다.
| $z^L_1 = $ |
$a^L_1 = $
|
| $z^L_2$ = |
$a^L_2 = $
|
| $z^L_3$ = |
$a^L_3 = $
|
| $z^L_4$ = |
$a^L_4 = $
|
$z^L_4$를 증가시키면 해당하는 출력 활성화 값인 a^L_4는 증가하고, 다른 출력 활성화 값들은 감소하는 것을 볼 수 있습니다. 마찬가지로 $z^L_4$를 감소시키면 $a^L_4$는 감소하고, 다른 모든 출력 활성화 값들은 증가합니다. 사실, 자세히 살펴보면 두 경우 모두 다른 활성화 값들의 총 변화량이 $a^L_4$의 변화량을 정확히 보상하는 것을 알 수 있습니다. 이 이유는 식 (78)과 약간의 대수를 사용하여 증명할 수 있듯이 출력 활성화 값들의 합은 항상 1이 되도록 보장되기 때문입니다.
$\begin{eqnarray} \sum_j a^L_j & = & \frac{\sum_j e^{z^L_j}}{\sum_k e^{z^L_k}} = 1.\tag{79}\end{eqnarray}$
결과적으로 $a^L_4$가 증가하면 다른 출력 활성화 값들은 합이 1이 되도록 동일한 총량만큼 감소해야 합니다. 물론 다른 모든 활성화 값들에 대해서도 비슷한 내용이 적용됩니다.
또한 식 (78)에서 지수 함수는 양수이므로 출력 활성화 값들이 모두 양수임을 의미합니다. 이는 소프트맥스 계층의 출력의 합이 1인 양수의 집합으로 간주될 수 있음을 의미합니다. 즉, 소프트맥스 계층의 출력은 확률 분포로 간주될 수 있습니다.
소프트맥스 계층이 확률 분포를 출력한다는 사실은 꽤나 만족스럽습니다. 많은 문제에서 출력 활성화 값이 $a^L_j$를 올바른 출력이 $j$일 확율에 대한 신경망의 추정치로 해석될 수 있다는 것은 편리합니다. 예를 들어 MNIST 숫자 분류 문제에서 $a^L_j$를 올바른 숫자 분류가 $j$일 확율에 대한 신경망의 추정치로 해석할 수 있습니다.
반대로 출력 계층이 시그모이드 계층이었다면 활성화 값들이 확률 분포를 형상한다고 가정할 수는 없었을 것입니다. 여기서 이를 명시적으로 증명하지는 않겠지만 시그모이드 계층의 활성화 값들이 일반적으로 확률 분ㅍ를 형성하지 않을 것이라는 점은 쉽게 짐작할 수 있습니다. 따라서 시그모이드 출력 계층에서는 출력 활성화 값에 대한 이처럼 간단한 해석을 할 수 없습니다.
비로소 우리는 소프트맥스 함수와 그 계층의 작동방식에 대하여 감을 잡기 시작했습니다. 지금까지의 내용을 요약하자면 식 (78)의 지수 함수는 모든 출력 활성화 값이 양수임을 보장하고 분모에 있는 합은 소프트맥스의 출력의 합이 1이 되도록 보장합니다. 따라서 그 특정 형태는 더 이상 그렇게 신비롭게 보이지 않습니다. 오히려 출력 활성화 값이 확률 분포를 형성하도록 하는 자연스로운 방법입니다. 소프트맥스를 $z^L_j$들을 재조정하고 그런 다음 그것들을 함께 압축하여 확률 분포를 형성하게 하는 방법으로 생각할 수 있습니다.
학습 속도 저하 문제: 이제 우리는 뉴런의 소프트맥스 계층에 대해 상당한 친숙함을 갖게 되었습니다. 그러나, 소프트맥스 계층이 어떻게 학습 속도 저하 문제를 해결하는지 아직 살펴보지 못했습니다. 이를 이해하기 위해 로그L_4를 증가시키면 해당하는 출력 활성화 값인 a^L_4는 증가하고, 다른 출력 활성화 값들은 감소하는 것을 볼 수 있습니다. 마찬가지로 $z^L_4$를 감소시키면 $a^L_4$는 감소하고, 다른 모든 출력 활성화 값들은 증가합니다. 사실, 자세히 살펴보면 두 경우 모두 다른 활성화 값들의 총 변화량이 $a^L_4$의 변화량을 정확히 보상하는 것을 알 수 있습니다. 이 이유는 식 (78)과 약간의 대수를 사용하여 증명할 수 있듯이 출력 활성화 값들의 합은 항상 1이 되도록 보장되기 때문입니다.
$\begin{eqnarray} \sum_j a^L_j & = & \frac{\sum_j e^{z^L_j}}{\sum_k e^{z^L_k}} = 1.\tag{79}\end{eqnarray}$
결과적으로 $a^L_4$가 증가하면 다른 출력 활성화 값들은 합이 1이 되도록 동일한 총량만큼 감소해야 합니다. 물론 다른 모든 활성화 값들에 대해서도 비슷한 내용이 적용됩니다.
또한 식 (78)에서 지수 함수는 양수이므로 출력 활성화 값들이 모두 양수임을 의미합니다. 이는 소프트맥스 계층의 출력의 합이 1인 양수의 집합으로 간주될 수 있음을 의미합니다. 즉, 소프트맥스 계층의 출력은 확률 분포로 간주될 수 있습니다.
소프트맥스 계층이 확률 분포를 출력한다는 사실은 꽤나 만족스럽습니다. 많은 문제에서 출력 활성화 값이 $a^L_j$를 올바른 출력이 $j$일 확율에 대한 신경망의 추정치로 해석될 수 있다는 것은 편리합니다. 예를 들어 MNIST 숫자 분류 문제에서 $a^L_j$를 올바른 숫자 분류가 $j$일 확율에 대한 신경망의 추정치로 해석할 수 있습니다.
반대로 출력 계층이 시그모이드 계층이었다면 활성화 값들이 확률 분포를 형상한다고 가정할 수는 없었을 것입니다. 여기서 이를 명시적으로 증명하지는 않겠지만 시그모이드 계층의 활성화 값들이 일반적으로 확률 분ㅍ를 형성하지 않을 것이라는 점은 쉽게 짐작할 수 있습니다. 따라서 시그모이드 출력 계층에서는 출력 활성화 값에 대한 이처럼 간단한 해석을 할 수 없습니다.
비로소 우리는 소프트맥스 함수와 그 계층의 작동방식에 대하여 감을 잡기 시작했습니다. 지금까지의 내용을 요약하자면 식 (78)의 지수 함수는 모든 출력 활성화 값이 양수임을 보장하고 분모에 있는 합은 소프트맥스의 출력의 합이 1이 되도록 보장합니다. 따라서 그 특정 형태는 더 이상 그렇게 신비롭게 보이지 않습니다. 오히려 출력 활성화 값이 확률 분포를 형성하도록 하는 자연스로운 방법입니다. 소프트맥스를 $z^L_j$들을 재조정하고 그런 다음 그것들을 함께 압축하여 확률 분포를 형성하게 하는 방법으로 생각할 수 있습니다.
학습 속도 저하 문제: 이제 우리는 뉴런의 소프트맥스 계층에 대해 상당한 친숙함을 갖게 되었습니다. 그러나, 소프트맥스 계층이 어떻게 학습 속도 저하 문제를 해결하는지 아직 살펴보지 못했습니다. 이를 이해하기 위해 로그와 유사한(log-likehood) 비용함수를 정의해보겠습니다. 신경망에 대한 학습 데이터로 $x$를 사용하고, 그에 상응하는 원하는 출력으로 $y$를 사용합니다. 그러면 이 학습데이터와 관련된 로그와 유사한 비용은 다음과 같습니다.
$\begin{eqnarray} C \equiv -\ln a^L_y.\tag{80}\end{eqnarray}$
예를 들어 MNIST 이미지로 학습하고 7의 이미지를 입력하면 로그와 유사한 비용함수로 계산한 비용은 $-ln a^L_7$입니다. 이것이 직관적으로 이해가 되는지 확인하기 위하여 신경망이 작업을 잘 수행하고 있는 경우, 즉 입력이 7이라고 확신하는 경우를 생각해보겠습니다. 이 경우 해당하는 확률 $a^L_7$에 대하여 1에 가까운 값을 추정하므로 비용 $-ln a^L_7$은 작아집니다. 반대로 신경망이 작업을 잘 수행하지 못하면 확률 $a^L_7$은 더 작아지고 비용 $-ln a^L_7$은 더 커집니다. 따라서 로그와 유사한 비용은 우리가 예상하는 비용 함수의 동작 방식과 같습니다.
학습 속도 저하 문제는 어떨까요? 이를 분석하기 위하여 학습 속도 저하의 핵심은 $\partial C / \partial w^L_{jk}$ 및 $\partial C / \partial b^L_j$ 값이 작아지는 것이라는 점을 다시 한번 상기하시기 바랍니다. 이에 대한 명시적인 유도과정은 생략하겠습니다. 연습삼아 직접 해보는 것도 좋을 것입니다. 약간의 대수학을 적용하면, 다음을 얻을 수 있습니다.
(여기서 용어를 약간 다르게 사용하고 있습니다. $y$를 신경망에서 원하는 출력을 나타내는데 사용했습니다. 7의 이미지가 입력되면 7을 출력하는 것이 그 예입니다. 하지만 다음 식에서는 $y$를 7에 해당하는 출력 활성화 벡터, 즉 7번째 위치에 1이 있고 나머지는 0인 벡터를 나타내는데 사용하고 있습니다.)
$\begin{eqnarray} \frac{\partial C}{\partial b^L_j} & = & a^L_j-y_j \tag{81}\\ \frac{\partial C}{\partial w^L_{jk}} & = & a^{L-1}_k (a^L_j-y_j) \tag{82}\end{eqnarray}$
위의 식들은 교차 엔트로피에 대한 이전 분석에서 얻은 식들과 동일합니다. 예를 들어 식 (82)를 식 (67)과 비교해 보십시오. 후자에서는 학습 데이터에 대해 평균을 냈지만 동일한 식입니다. 그리고 이전 분석에서와 마찬가지로 이러한 식은 학습 속도 저하가 발생하지 않도록 보장합니다. 사실 로그와 유사한 비용을 사용하는 소프트맥스 출력 계층은 교차 엔트로피 비용을 사용하는 시그모이드 출력 계층과 매우 유사합니다. 이러한 유사성을 감안할 때 시그모이드 출력 계층과 교차 엔트로피를 사용해야할까요, 아니면 소프트맥스 출력 계층과 로그와 유사한 비용을 사용해야할까요? 사실 많은 상황에서 두 가지 접근 방식 모두 잘 작동합니다. 이번 장의 나머지 부분에서는 교차 엔트로피 비용을 사용하는 시그모이드 출력 계층을 사용합니다. 나중에 6장에서는 때때로 로그와 유사한 비용을 사용하는 소프트맥스 출력 계층을 사용합니다. 이렇게 전환하는 이유는 일부 후반 신경망을 특정 영향력 있는 학술 논문에 나오는 신경망과 더 유사하게 만들기 위해서입니다. 더 일반적인 원칙으로서 출력 활성화 값을 확률로 해석하려는 경우 소프트맥스와 로그와 유사한 비용을 사용하는 것이 좋습니다. 이것은 항상 중요한 것은 아니지만 MNIST와 같이 분리된 클래스를 포함하는 분류 문제에서 유용할 수 있습니다.
과적합 및 정규화 (Overfitting and regularization)
노벨 물리학상을 수상한 엔리코 페르미는 동료들이 중요한 미해결 물리학 문제에 대한 해결책으로 제시한 수학적 모델에 대한 의견을 묻는 질문을 받은 적이 있습니다. 그 모델은 실험 결과와 훌륭하게 일치했지만, 페르미는 회의적이었습니다. 그는 모델에서 설정할 수 있는 자유 매개변수가 몇 개인지 물었습니다. "4개"라는 답변이 돌아왔습니다. 페르미는 다음과 같이 대답했습니다. "내 친구 조니 폰 노이만이 이런 말을 하곤 했던 것이 기억나네. 매개변수 네 개면 코끼리도 맞출 수 있고, 다섯 개면 코끼리 코도 흔들게 만들 수 있다고 말이야."
물론 요점은 많은 수의 자유 매개변수를 가진 모델은 놀라울 정도로 광범위한 현상을 설명할 수 있다는 것입니다. 그러한 모델이 사용 가능한 데이터와 잘 일치하더라도 그것이 좋은 모델이라는 의미는 아닙니다. 그것은 단지 모델에 주어진 크기의 거의 모든 데이터 세트를 설명할 수 있을 만큼 충분한 자유도가 있다는 의미일 수 있으며, 근본 현상에 대한 진정한 통찰력을 포착하지 못할 수 있습니다. 그런 일이 발생하면 모델은 기존 데이터에 대해서는 잘 작동하지만 새로운 상황으로 일반화하는 데 실패합니다. 모델의 진정한 테스트는 이전에 노출된 적이 없는 상황에서 예측을 수행하는 능력입니다.
페르미와 폰 노이만은 4개의 매개변수를 가진 모델을 의심했습니다. MNIST 숫자를 분류하는 우리의 30개의 은닉 뉴런 신경망은 거의 24,000개의 매개변수를 가지고 있습니다. 이것은 아주 많은 매개변수입니다. 우리의 100개의 은닉 뉴런을 가진 신경망은 거의 80,000개의 매개변수를 가지고 있으며 최첨단 신경망은 종종 수백만 또는 수십억 개의 매개변수를 가집니다. 우리는 그 결과를 신뢰해야할까요?
새로운 상황으로 일반화하는데 신경망이 제대로 작동하지 못하는 상황을 구성하여 이 문제를 더 명확히 해보겠습니다. 23,860개의 매개변수를 가진 30개의 은닉 뉴런 신경망을 사용해보도록 하겠습니다. 하지만 50,000개의 모든 MNIST 학습 데이터를 사용하여 신경망을 학습시키지는 않겠습니다. 1,000개의 학습 데이터만 사용해보도록 하겠습니다. 그 제한된 데이터 세트를 사용하면 일반화 문제가 훨씬 더 분명해질 것입니다. 이전과 유사한 방식으로 교차 엔트로피 비용함수를 사용하고, 학습률 $\eta = 0.5$와 미니 배치 크기 10을 사용하여 신경망을 학습시키도록 하겠습니다. 그러나 학습 데이터 개수가 적기 때문에 이전보다 다소 많은 400 에포크 동안 학습을 수행하도록 하겠습니다. 비용함수가 어떻게 변하는지 보기 위해서 network2를 사용해보겠습니다.
>>> import mnist_loader >>> training_data, validation_data, test_data = \ ... mnist_loader.load_data_wrapper() >>> import network2 >>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost) >>> net.large_weight_initializer() >>> net.SGD(training_data[:1000], 400, 10, 0.5, evaluation_data=test_data, ... monitor_evaluation_accuracy=True, monitor_training_cost=True)
* 주석: 위 실행을 위한 network2.py와 run3.py는 이 링크에서 받을 수 있다. (python 3.13 환경에서 구동 가능)
위의 실행결과를 바탕으로 신경망이 학습하면서 비용이 변하는 과정을 아래와 같은 그래프로 나타낼 수 있습니다.

이제 학습 데이터에 대한 분류 정확도가 시간에 따라 어떻게 변하는지 살펴보겠습니다.
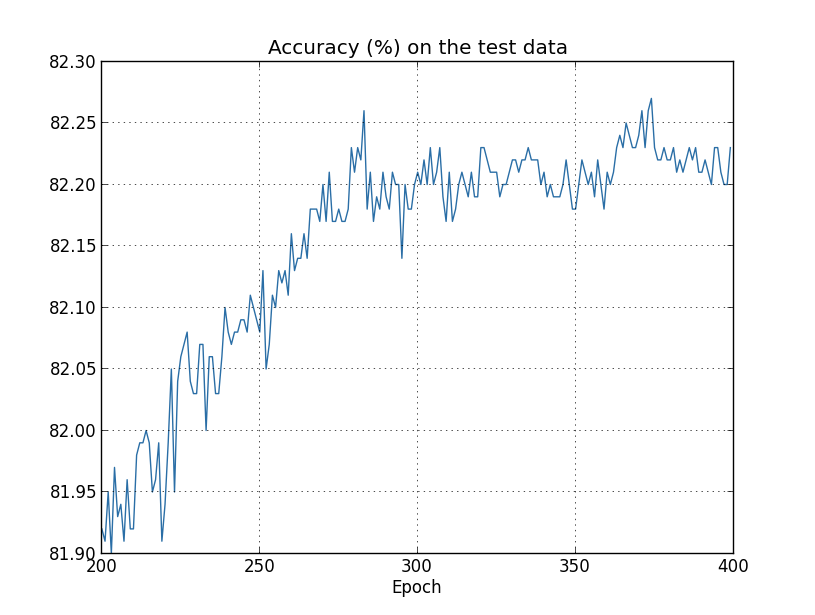
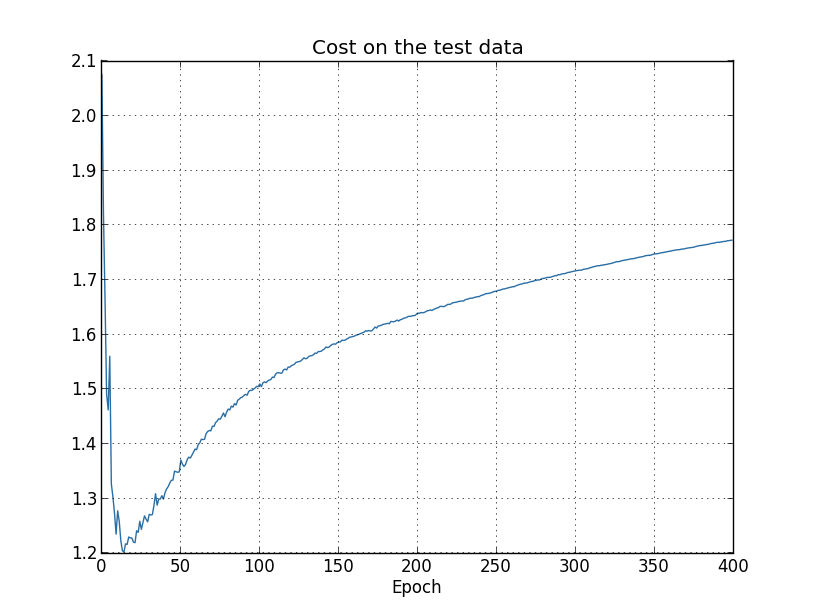
여기서 문제가 테스트 데이터에 대한 분류 정확도가 아니라 학습 데이터에 대한 비용을 보고 있기 때문인지 궁금할 수 있습니다. 즉, 어쩌면 우리가 사과와 오렌지를 비교하는 것일 수 있습니다. 비슷한 측정값을 비교하기 위해 학습 데이터의 비용과 테스트 데이터의 비용을 비교하면 어떨까요? 아니면 학습 데이터와 테스트 데이터 모두에 대한 분류 정확도를 비교할 수도 있을까요? 실제로 어떻게 비교하든 세부적인 것은 바뀔 수 있어도 본질적으로 동일한 현상이 나타납니다. 예를 들어 테스트 데이터의 비용을 살펴보겠습니다.
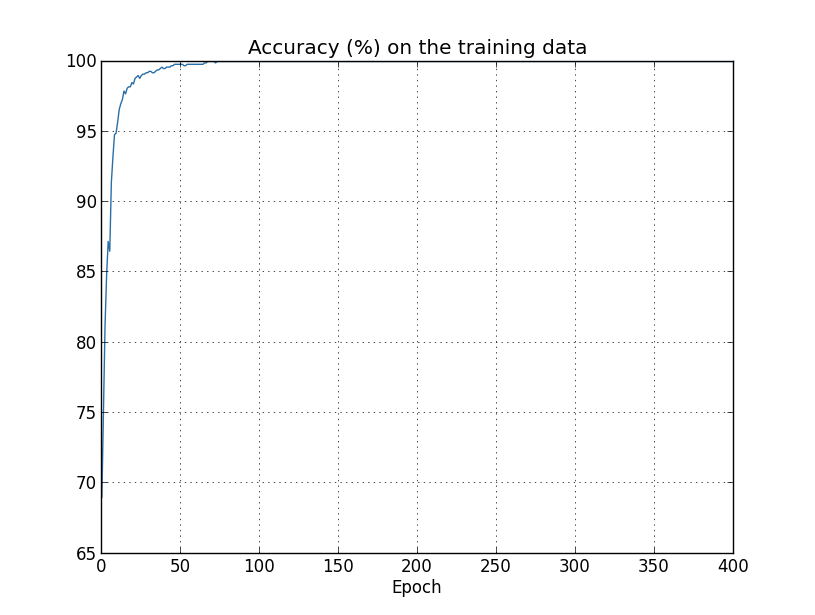
과적합의 또 다른 징후는 학습 데이터의 분류 정확도에서 볼 수 있습니다.
과적합은 신경망의 주요한 문제입니다. 이는 종종 매우 많은 수의 가중치와 편향을 갖는 최신 네트워크에서 특히 그렇습니다. 효과적으로 훈련하면 과적합이 진행 중인지 감지하여 과훈련을 방지할 수 있는 방법이 필요합니다. 그리고 과적합의 영향을 줄일 수 있는 기술도 필요합니다.
과적합을 감지하는 분명한 방법은 위에서 사용한 접근 방식을 사용하는 것입니다. 즉, 신경망을 훈련하는 동안 테스트 데이터에 대한 정확도를 추적하는 것입니다. 테스트 데이터에 대한 정확도가 더 이상 향상되지 않으면 학습을 중단해야합니다. 물론 엄밀히 말하면 이는 반드시 과적합의 징후는 아닙니다. 테스트 데이터와 학습 데이터 모두에 대한 정확도가 동시에 향상되지 않을 수도 있습니다. 하지만 이 전략을 채택하면 과적합을 방지할 수 있습니다.
실제로 우리는 이 전략을 변형하여 사용할 것입니다. MNIST 데이터를 불러올 때 세가지 종류로 구분하여 불러온다는 것을 상기해주시기 바랍니다.
>>> import mnist_loader >>> training_data, validation_data, test_data = \ ... mnist_loader.load_data_wrapper()
지금까지 우리는 training_data와 test_data를 사용해 왔고, valiation_data는 무시해왔습니다. validation_data는 MNIST 학습 데이터 50,000개 이미지, 테스트 데이터 10,000개 이미지와 다른 10,000개의 숫자 이미지로 구성되어 있습니다. 과적합을 방지하기 위하여 test_data 대신 validation_data를 사용할 것입니다. 이를 위해서 위에서 test_data에 대해 설명한 것과 거의 동일한 전략을 사용할 것입니다. 즉, 각 에포크의 마지막에 validation_data에 대한 분류 정확도를 계산할 것입니다. validation_data에 대한 분류 정확도가 포화가 되면 학습을 중단할 것입니다. 이 전략을 조기 종료(early stopping)이라고 합니다. 물론 실제로는 정확도가 언제 포화되는지 즉시 알 수 없습니다. 대신 정확도가 포화되었다고 확신할 때까지 훈련을 계속합니다.
(언제 중단해야할 지 결정하려면 어느 정도 판단이 필요합니다. 이전 그래프에서 280번째 에포크를 정확도가 포화된 시점으로 표시했습니다. 아마도 너무 비관적이었을 수도 있습니다. 신경망은 학습 중에 잠시동안 고점에 도달했다가 계속 개선되는 경우가 있습니다. 400번째 에포크 이후에도 더 많은 학습이 일어날 수 있다고 해도 놀라운 사실은 아닙니다. 다만, 추가 개선 규모가 작을 가능성이 높습니다. 따라서 조기 종료를 위한 덜 공격적인 전략을 채택할 수 있습니다.)
왜 과적합을 방지하기 위해 test_data가 아닌 validation_data를 사용할까요? 사실 이것은 더 일반적인 전략의 일부입니다. 즉, 훈련할 에포크의 수, 최적 신경망 구조 등과 같은 다양한 하이퍼파라미터의 시험적 선택을 평가하기 위해 validation_data를 사용하는 것입니다. 우리는 이러한 평가를 활용하여 하이퍼파라미터에 대한 적절한 값을 찾아 설정할 수 있습니다. 사실 지금까지 언급하지 않았지만 이것이 부분적으로 이 책의 앞부분에서 하이퍼파라미터를 선택한 방법입니다. (이에 대한 자세한 내용은 나중에 다시 다루도록 하겠습니다.)
물론 이것이 test_data 대신 validation_data를 사용하여 과적합을 방지하는지에 대한 질문에 대한 답이 되는 것은 아닙니다. 대신, 왜 좋은 하이퍼파라미터를 설정하기 위하여 test_data 대신 validation_data를 사용하는지에 대한 더 일반적인 질문으로 바뀝니다. 그 이유를 이해하기 위해 하이퍼파라미터를 설정할 때 다양한 하이퍼파라미터 선택을 시도할 가능성이 높다는 점을 유념해주시기 바랍니다. test_data에 대한 평가를 기반으로 하이퍼파라미터를 선택하면 결국 하이퍼파라미터를 test_data에 과적합시킬 수 있습니다. 즉, test_data의 특정 특성에 맞는 하이퍼파라미터를 찾았지만 신경망의 성능이 다른 데이터들에는 일반화되지 않는 결과가 나올 수 있습니다. 우리는 validation_data를 사용하여 하이퍼파리미터를 파악함으로써 이를 방지할 수 있습니다. 그런 다음 원하는 하이퍼파라미터를 얻으면 test_data를 사용하여 정확도에 대한 최종 평가를 수행할 수 있습니다. 이를 통해 test_data에 대한 결과가 우리 신경망이 얼마나 잘 일반화되었는지에 대한 진정한 척도라는 확신을 가질 수 있습니다. 다시 말해, 검증 데이터는 좋은 하이퍼파라미터를 학습하는데 도움이 되는 일종의 학습 데이터로 생각할 수 있습니다. 검증 데이터를 학습데이터와 분리하여 적절한 하이퍼파라미터를 찾는 접근 방식을 홀드아웃 방법(hold out method, 데이터 분할 방법)이라고 부릅니다.
이제 실제로 test_data에 대한 성능을 평가한 후에도 신경망 구조를 바꾸는 등 다른 접근 방법을 시도해보고 싶을 수도 있습니다. 이 경우 새로운 하이퍼파리미터들을 다시 찾아야할 것입니다. 이렇게 하면 결국 test_data에도 과적합될 위험이 있지 않을까요? 결과과 일반화될 것이라고 확신하면 잠재적으로 무한한 데이터 세트가 필요할까요? 이 우려 사항을 완전히 해결하는 것은 정말 어려운 문제입니다. 하지만 우리의 실제적인 목적을 위해 이질문에 대해 너무 걱정하지 않을 것입니다. 대신 위에서 설명한 것처럼 training_data, validation_data, test_data를 기반으로 기본적인 홀드아웃 방법을 사용하여 계속 진행할 것입니다.
지금까지는 1,000개의 학습 이미지만 사용하는 경우의 과적합만 살펴보았습니다. 50,000개의 학습 데이터를 사용하면 어떨까요? 다른 모든 매개변수(30개의 은닉 뉴런, 학습률 0.5, 미니 배치 크기 10)는 그대로 유지하되, 모든 50,000개의 이미지를 사용하여 30번의 에포크 동안 학습합니다. 다음은 학습 데이터와 테스트 데이터 모두에 대한 분류 정확도 결과를 보여주는 그래프입니다. 이전 그래프와 결과를 더 직접적으로 비교하기 위해 여기서는 검증 데이터 대신 테스트 데이터를 사용했다는 점에 유의하세요.

보시다시피, 1,000개의 학습 예제를 사용했을 때보다 테스트 데이터와 학습 데이터의 정확도가 훨씬 더 가깝게 유지됩니다. 특히 학습 데이터에 대한 최상의 분류 정확도인 97.86%는 테스트 데이터의 95.33%보다 2.53% 더 높을 뿐입니다. 이는 이전의 17.73% 차이에 비해 훨씬 줄어든 숫자입니다. 과적합이 여전히 발생하고 있지만 크게 줄었습니다. 우리 신경망은 학습 데이터에서 학습한 내용을 테스트 데이터로 훨씬 더 잘 일반화하여 적용할 수 있습니다. 일반적으로 과적합을 줄이는 가장 중요한 방법 중 하나는 학습 데이터의 크기를 늘리는 것입니다. 충분한 학습 데이터가 있으면 매우 큰 신경망 조차도 과적합되기 어렵습니다. 불행히도 학습 데이터는 비용이 많이 들거나 얻기 어려울 수 있으므로 항상 실용적인 선택지는 아닙니다.
정규화(Regularization)
학습 데이터의 양을 늘리는 것이 과적합을 줄이는 한가지 방법이라고 했습니다. 과적합이 발생하는 정도를 줄일 수 있는 다른 방법은 없을까요? 한 가지 가능한 접근 방식은 신경망의 크기를 줄이는 것입니다. 그러나 큰 신경망은 작은 신경망보다 더 강력할 수 있으며, 따라서 이는 더 선택할 것이 없을 때 선택할만한 것입니다.
다행히 신경망과 학습 데이터를 변경할 수 없어도 과적합을 줄일 수 있는 다른 기술이 있습니다. 이를 정규화(regularization) 기술이라고 합니다. 이번 섹션에서는 가장 일반적으로 사용되는 정규화 기술 중에 하나인 가중치 감소(weight decay) 또는 L2 정규화라고 하는 기술에 대하여 설명하도록 하겠습니다. L2 정규화는 비용 함수에 추가적인 항, 즉 정규화 항(regularization term)이라고 하는 항을 추가하는 것입니다. 다음은 정규화 항이 적용된 교차 엔트로피입니다.
$\begin{eqnarray} C = -\frac{1}{n} \sum_{xj} \left[ y_j \ln a^L_j+(1-y_j) \ln (1-a^L_j)\right] + \frac{\lambda}{2n} \sum_w w^2.\tag{85}\end{eqnarray}$
위 식의 첫번째 항은 일반적인 교차 엔트르피 표현식입니다. 하지만 두번째 항, 즉 신경망 내의 모든 가중치의 제곱을 합하는 항을 추가했습니다. 이 항은 $\lambda / 2n$을 계수로 가집니다. 여기서 $\lambda > 0$를 정규화 파라미터라고 하며, $n$은 우리 학습 데이터의 크기입니다. $\lambda$를 어떻게 설정하는지에 대해서는 나중에 다루도록 하겠습니다. 또한 정규화 항에 편향이 포함되어 있지 않다는 점도 기억해주시기를 바랍니다. 이에 대해서도 나중에 언급하겠습니다.
물론 이차 비용과 같은 다른 비용 함수에도 정규항을 포함시키는 것이 가능합니다. 이는 비슷한 방법으로 이루어집니다.
$\begin{eqnarray} C = \frac{1}{2n} \sum_x \|y-a^L\|^2 + \frac{\lambda}{2n} \sum_w w^2.\tag{86}\end{eqnarray}$
두 경우 모두 정규화된 비용함수를 다음과 같이 쓸 수 있습니다. ($C_0$는 원래의 정규화되지 않은 비용 함수입니다.)
$\begin{eqnarray} C = C_0 + \frac{\lambda}{2n} \sum_w w^2,\tag{87}\end{eqnarray}$
직관적으로 말하면 정규화의 효과는 다른 조건이 동일할 때 신경망이 작은 가중치를 선호하도록 만드는 것입니다. 큰 가중치는 비용 함수의 첫번째 부분을 크게 개선하는 경우에만 해당합니다. 다르게 말하자면 정규화는 작은 가중치를 찾는 것과 원래 비용 함수를 최소화하는 것 사이에서 절충하는 방법으로 볼 수 있습니다. 절충의 두 요소의 상대적인 중요성은 $\lambda$값에 따라 달라집니다. $\lambda$가 작을 때는 원래 비용 함수를 최소화하는 것을 선호하지만 $\lambda$가 클 때에는 작은 가중치를 선호합니다.
아직까지 왜 이러한 종류의 절충이 과적합을 줄이는 데 도움이 되는지는 명확하지 않습니다. 하지만 실제로 그렇다는 것이 밝혀졌습니다. 이것에 대해서는 다음 섹션에서 다루겠습니다. 하지만 먼저 정규화가 실제로 과적합을 줄인다는 것을 보여주는 예제를 살펴보겠습니다.
이러한 예제를 구성하려면 정규화된 신경망에서 확률적 경사 하강법 알고리즘을 적용하는 방법을 알아야합니다. 특히 신경망의 모든 가중치와 편향에 대해 편미분 $\partial C / \partial w$와 $\partial C / \partial b$를 계산하는 방법을 알아내야 합니다. 식 (87)을 편미분하면 아래 식을 얻을 수 있습니다.
$\begin{eqnarray} \frac{\partial C}{\partial w} & = & \frac{\partial C_0}{\partial w} + \frac{\lambda}{n} w \tag{88}\\ \frac{\partial C}{\partial b} & = & \frac{\partial C_0}{\partial b}.\tag{89}\end{eqnarray}$
$\partial C / \partial w$와 $\partial C / \partial b$ 항은 지난 장에서 설명한 대로 역전파를 사용하여 계산할 수 있습니다. 따라서 정규화된 비용함수의 기울기를 쉽게 계산할 수 있다는 것을 알 수 있습니다. 평소처럼 역ㅇ전파를 사용한 다음 모든 가중치 항의 편미분에 $(\lambda / n) + w$를 더하면 됩니다. 편향에 대한 편미분은 변경되지 않으므로 편향에 대한 경사 하강법 학습 규칙은 일반적인 규칙과 다르지 않습니다.
$\begin{eqnarray} b & \rightarrow & b -\eta \frac{\partial C_0}{\partial b}.\tag{90}\end{eqnarray}$
가중치에 대한 학습규칙은 다음과 같습니다.
$\begin{eqnarray} w & \rightarrow & w-\eta \frac{\partial C_0}{\partial w}-\frac{\eta \lambda}{n} w \tag{91}\\ & = & \left(1-\frac{\eta \lambda}{n}\right) w -\eta \frac{\partial C_0}{\partial w}. \tag{92}\end{eqnarray}$
이것은 일반적인 경사 하강법 학습 규칙과 동일하지만 먼저 가중치 $w$를 $1 - \frac {n \lambda}{n}$의 비율로 재조정합니다. 이 재조정을 때로는 가중치를 더 작게 만들기 때문에 가중치 감소라고 합니다. 얼핏 보면 이것이 가중치가 멈출 수 없이 0으로 향하게 된다는 것을 의미하는 것처럼 보입니다. 하지만 그렇지 않습니다. 다른 항이 가중치를 증가시킬 수 있기 때문입니다. 그렇게 하면 정규화되지 않은 비용 함수가 감소합니다.
이것이 경사 하강법이 작동하는 방식입니다. 확률적 경사 하강법은 어떻습니까? 글쎄요, 정규화되지 않은 확률적 경사 하강법에서와 마찬가지로 $m$개의 학습 데이터로 이루어진 미니 배치를 평균하여 $\partial C / \partial w$를 추정할 수 있습니다. 따라서 확률적 경사 하강법에 대한 정규화된 학습 규칙은 다음과 같습니다. (식 (20) 참조) (여기서 합은 미니 배치의 학습 데이터 $x$에 대한 것이고, $C_x$는 학습 데이터에 대한 정규화되지 않은 비용입니다.)
$\begin{eqnarray} w \rightarrow \left(1-\frac{\eta \lambda}{n}\right) w -\frac{\eta}{m} \sum_x \frac{\partial C_x}{\partial w}, \tag{93}\end{eqnarray}$
이것은 $1 - \frac {n \lambda}{n}$라는 가중치 감소 계수를 제외하고는 확률적 경사 하강법에 대한 일반적인 규칙과 정확하게 동일합니다. 마지막으로 완전성을 위해 편향에 대한 정규화된 학습 규칙을 설명하겠습니다. 물론 이것은 정규화되지 않은 경우와 정확히 동일합니다. (식 (21) 참조) (아래 식에서 합은 미니 배치의 학습 데이터 $x$에 대한 것입니다.)
$\begin{eqnarray} b \rightarrow b - \frac{\eta}{m} \sum_x \frac{\partial C_x}{\partial b},\tag{94}\end{eqnarray}$
신경망의 성능이 정규화에 따라 어떻게 변하는지 살펴보도록 하겠습니다. 30개의 은닉 뉴런, 미니 배치의 크기 10, 학습률 0.5, 교차 엔트로피 비용 함수를 사용하는 신경망을 이전과 같이 사용하도록 하겠습니다. 그러나 이번에는 정규화 파라미터 $\lambda = 0.1$을 사용할 것입니다. 이 코드에서는 lambda가 Python에서 예약어(주: 파이선에서 lambda는 익명함수를 만들때 사용하는 키워드)이므로 변수명으로 lmbda를 사용합니다. 또한, 검증 데이터가 아닌 테스트 데이터를 다시 사용했습니다. 엄밀히 말하면 앞서 논의한 모든 이유로 검증 데이터를 사용해야합니다. 하지만 정규화를 적용한 결과를 이전의 결과와 더 직접적으로 비교할 수 있으므로 테스트 데이터를 사용하는 것임을 미리 밝히고자 합니다. 검증 데이터를 사용하도록 코드를 변경하는 일은 그리 어렵지 않은 일이며, 유사한 결과를 얻을 수 있습니다.
>>> import mnist_loader >>> training_data, validation_data, test_data = \ ... mnist_loader.load_data_wrapper() >>> import network2 >>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost) >>> net.large_weight_initializer() >>> net.SGD(training_data[:1000], 400, 10, 0.5, ... evaluation_data=test_data, lmbda = 0.1, ... monitor_evaluation_cost=True, monitor_evaluation_accuracy=True, ... monitor_training_cost=True, monitor_training_accuracy=True)
* 주석: 교차 엔트로피를 사용한 network2.py와 run4.py는 이 링크에서 받을 수 있다. (python 3.13 환경에서 구동 가능)
학습 데이터에 대한 비용은 이전의 정규화되지 않은 경우와 마찬가지로 전체 시간 동안 감소합니다.
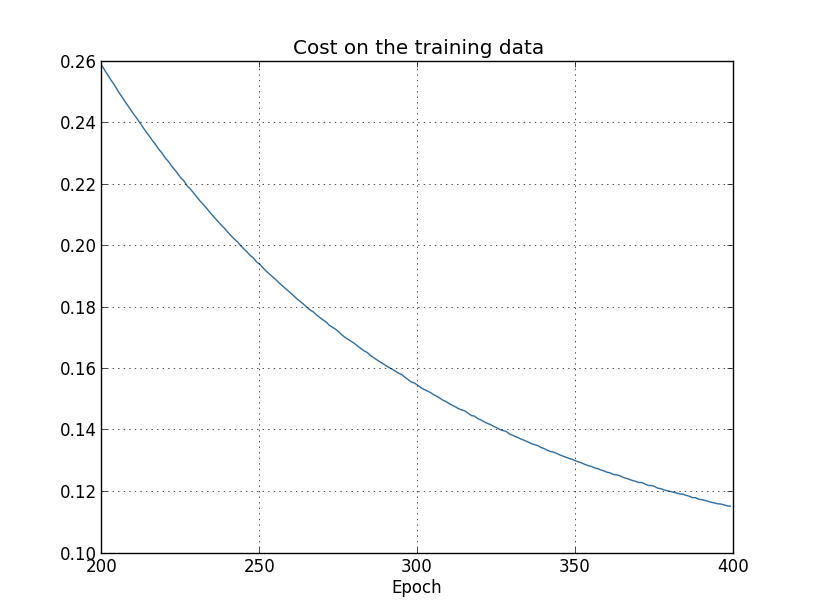

분명히 정규화는 과적합을 억제하는 효과를 발휘합니다. 더욱이 정확도는 상당히 높아서 정규화하기 전에 얻은 최고점인 82.27%에 비해 87.1%의 분류 정확도를 보였습니다. 실제로 400번의 에포크를 넘어서 계속 학습하면 훨씬 더 나은 결과를 얻을 수 있습니다. 경험적으로 볼 때, 정규화는 우리 신경망이 더 잘 일반화되도록 하고 과적합의 영향을 상당히 줄이는 것을 확인할 수 있습니다.
1,000개의 학습 이미지만 있는 인위적인 환경에서 벗어나 50,000개의 전체 학습 데이터를 활용하면 어떻게 될까요? 물론, 우리는 이미 50,000개의 전체 이미지에서 과적합이 훨씬 덜 문제가 된다는 것을 확인했습니다. 그렇다 하더라도 정규화를 적용할 필요가 있을까요? 이전과 동일한 하이퍼파라미터 (30 에포크, 학습률 0.5, 미니 배치 크기 10)를 유지해보도록 하겠습니다. 그러나 정규화 파라미터는 수정해야합니다. 그 이유는 학습 데이터의 크기 $n$이 1,000에서 50,000으로 변경되었고, 이로 인해 가중치 감소 계수 $1 - \frac {\eta\lambda}{n}$도 달라졌기 때문입니다. $\lambda = 0.1$을 계속 사용하면 가중치 감소가 훨씬 적어지고 따라서 정규화의 효과도 훨씬 적어질 것입니다. 이를 보상하기 위하여 $\lambda = 0.5$으로 변경하도록 하겠습니다.
>>> net.large_weight_initializer() >>> net.SGD(training_data, 30, 10, 0.5, ... evaluation_data=test_data, lmbda = 5.0, ... monitor_evaluation_accuracy=True, monitor_training_accuracy=True)
* 주석: 앞서 run4.py를 조금 변경하면 위의 실행은 가능하므로 실행코드는 생략합니다.
이로써 우리는 아래의 결과를 얻을 수 있습니다.
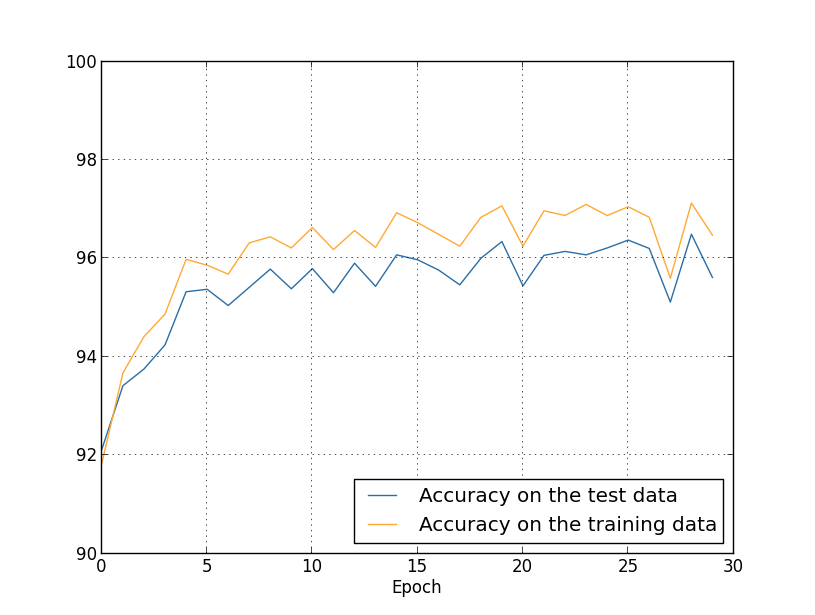
여기에는 좋은 소식이 많이 있습니다. 첫째, 테스트 데이터에 대한 분류 정확도가 정규화를 적용하지 않았을 때에 비하여 95.49%에서 96.49%로 향상되었습니다. 이는 큰 개선입니다. 둘째, 학습 데이터와 테스트 데이터 결과 사이의 격차가 이전보다 훨씬 좁아져서 1% 미만인 것을 확인할 수 있습니다. 여전히 상당한 격차이지만 과적합을 줄이는데 상당한 진전을 이루었습니다.
마지막으로 100개의 은닉 뉴런과 정규화 파라미터 $\lambda = 5.0$을 사용했을 때 얻을 수 있는 데스트 분류 정확도를 살펴보겠습니다. 여기서 과적합에 대한 자세한 분석은 하지 않겠습니다. 순전히 재미로 우리의 새로운 기술은 교차 엔트로피 비용 함수와 L2 정규화를 사용하여 얼마나 높은 정확도를 얻을 수 있는지 확인하기 위한 것입니다.
>>> net = network2.Network([784, 100, 10], cost=network2.CrossEntropyCost) >>> net.large_weight_initializer() >>> net.SGD(training_data, 30, 10, 0.5, lmbda=5.0, ... evaluation_data=validation_data, ... monitor_evaluation_accuracy=True)
* 주석: 앞서 run4.py를 조금 변경하면 위의 실행은 가능하므로 실행코드는 생략합니다.
최종 결과는 검증 데이터에 대한 분류 정확도가 97.92%입니다. 이는 30개의 은닉 뉴런을 사용했을때 보다 크게 향상된 수치입니다. 실제로 $\eta = 0.1$과 $\lambda = 5.0$으로 60 에포크 동안 실행하도록 약간만 조정하면 98%의 장벽을 넘어 검증 데이터에서 98.04%의 분류 정확도를 달성할 수 있습니다. 코드가 152줄 밖에 안된다는 점을 고려하면 나쁘지 않습니다.
정규화는 과적합을 줄이고 분류 정확도를 높이는 방법이라고 설명했습니다. 사실 이것이 유일한 이점은 아닙니다. 경험적으로 여러 번의 MNIST 신경망 학습을 실행해 보면, 무작위로 초기화된 가중치를 사용하다보면 때때로 정규화되지 않은 학습은 비용 함수의 "지역 최소값"에 갇힌 듯 "멈추는" 것을 발견할 수 있습니다. 그 결과 다른 학습 실행과는 상당히 다른 결과가 나타납니다. 반대로 정규화를 적용한 학습 실행은 훨씬 더 쉽게 재현 가능한 결과를 얻을 수 있습니다.
왜 이런 일이 벌어질까요? 경험적으로 비용 함수가 정규화되지 않을 경우 다른 조건이 동일할 때, 가중치 벡터의 길이가 늘어날 가능성이 높습니다. 시간이 지남에 따라 이는 실제로 매우 큰 가중치 벡터로 이어질 수 있습니다. 이 경우 경사 하강으로 인한 가중치의 변경이 가중치의 방향에 아주 작은 변화만 주기 때문에 가중치 벡터가 거의 같은 방향을 가리키는 상태로 갇히기 쉽습니다. 이러한 현상은 학습 알고리즘이 가중치 공간을 제대로 탑색하는 것을 어렵게 만들고 결과적으로 비용 함수의 좋은 최소값을 찾는 것을 더 어렵게 만듭니다.
정규화가 과적합을 줄이는 데 도움이 되는 이유
경험적으로 정규화가 과적합을 줄이는 데 도움이 된다는 사실을 확인했습니다. 이는 고무적이지만 불행히도 왜 정규화가 도움이 되는지 명확하지 않습니다. 사람들이 흔히 설명하는 이야기는 다음과 같습니다. 작은 가중치는 어떤 의미에서 복잡성이 낮으므로 데이터에 대한 더 간단하고 강력한 설명을 제공하며 따라서 선호되어야 합니다. 하지만 이 이야기는 너무 간결하며, 다소 의심스럽가나 불가해 보이는 여러 요소를 포함하고 있습니다. 이 이야기를 조금 더 자세히 살펴보고 비판적으로 검토해보겠습니다. 이를 위해 (신경망) 모델을 구축하고자 하는 간단한 데이터들이 있다고 가정해 봅시다.

이는 암묵적으로 실제 데이터인 $x$와 $y$로 어떠한 실제 실제 현상을 연구하는 것입니다. 우리의 목표는 $x$의 함수로 $y$를 예측할 수 있는 모델을 구축하는 것입니다. 이러한 모델을 구축하기 위해 신경망을 사용할 수도 있지만 훨씬 더 간단한 방법을 시도해 보겠습니다. $y$를 $x$에 대한 다항식으로 모델링하려고 합니다. 신경망 대신 다항식을 사용하는 이유는 다항식을 사용하면 모든 것이 투명하게 살펴볼 수 있기 때문입니다. 다항식의 경우를 이해한 후에는 신경망으로 우리의 설명을 확장할 것입니다. 위 그래프에서는 10개의 점이 있으므로 데이터를 정확하게 나타내는 고유한 9차 다항식 $y = a_0x^9 + a_1x^8 + ... + a_9$을 구해볼 수 있습니다. 다음은 이렇게 구한 9차 다항식의 그래프입니다.

이 다항식은 모든 점들과 정확하게 일치합니다. 그러나, 우리는 선형 모델 $y = 2x$를 사용해도 상당히 좋은 결과를 얻을 수 있습니다.

이 두 모델 중에 어느 것이 더 나은 모델일까요? 어떤 것이 더 진실일 가능성이 높을까요? 그리고 어떤 모델이 동일한 기본 실제 현상의 다른 예를 더 잘 일반화하고 있을 가능성이 높을까요?
이러한 질문들에 답하는 것은 쉽지 않습니다. 사실, 기본 실제 현상에 대한 훨씬 더 많은 정보 없이는 위의 어떤 질문에 확실하게 답할 수 없습니다. 하지만 두 가지 가능성을 고려해 봅시다. (1) 9차 다항식이 실제로 실제 현상을 진정으로 설명하는 모델이며, 따라서 완벽하게 일반화할 수 있을 것이다. (2) 올바른 모델은 $y = 2x$이지만, 예를 들어 측정 오류로 인해 약간의 추가 노이즈가 있으며, 이것이 모델이 정확하게 들어맞지 않는 이유이다.
이 두 가지 가능성 중 어느 것이 맞는지 (호은 실제로 어떤 세 번째 가능성이 존재하는지) 선험적으로 말할 수는 없습니다. 논리적으로 둘 다 사실일 수 있습니다. 그리고 이것은 사소한 차이가 아닙니다. 제공된 데이터만 놓고 보면 두 모델 간에 약간의 차이가 존재한다는 것은 명백한 사실입니다. 하지만 위의 그래프에 표시된 어떤 값보다 훨씬 더 큰 $x$값에 해당하는 $y$값을 예측하려고 한다고 가정해 봅시다. 그렇게 하려고 하면 두 모델의 예측 사이에 극적인 차이가 있을 것입니다. 9차 다항식 모델은 $x^9$항에 의해 지배되는 반면, 선형 모델은 여전히 선형으로 유지되기 때문입니다.
한 가지 관점은 과학에서 부득이한 경우가 아니라면 더 간단한 설명을 선택해야 한다는 것입니다. 많은 데이터가 나타내는 점들을 설명하는 것처럼 보이는 간단한 모델을 발견했을 때 우리는 "유레카!"라고 외치고 싶어집니다. 결국, 간단한 설명이 단순히 우연하게 발생할 가능성은 낮아 보입니다. 오히려 우리는 그 모델이 현상에 대한 어떤 근본적인 진실을 표현하고 있다고 생각합니다. 현재의 경우 모델 $y = 2x$가 $y = a_0x^9 + a_1x^8 + ... + a_9$보다 훨씬 더 간단해 보입니다. 그러한 단순함이 우연히 발생했다면 놀라울 것이며, 따라서 우리는 $y = 2x + noise$가 어떤 근본적인 진실을 표현하고 있다고 생각합니다. 따라서 9차 다항식 모델은 이러한 특정 데이터가 나타내는 점들에 대해서는 완벽하게 맞아 떨어지지만 다른 데이터들이 나타내는 점들에 대해서는 일반적으로 적용되지 못할 것이며, 노이즈가 있는 선형 모델이 더 큰 예측력을 가질 것입니다.
신경망의 관점에서 이것이 무엇을 의미하는지 살펴봅시다. 정규화된 신경망에서와 같이 신경망의 가중치가 대부분 작다고 가정해 봅시다. 작은 가중치는 우리가 몇 개의 임의의 임력을 여기 저기서 변경해도 신경망의 동작이 크게 변하지 않는다는 것을 의미합니다. 이는 정규화된 신경망이 데이터의 국소적인 노이즈의 영향을 학습하게 어렵게 만듭니다. 네트워크의 출력에 단일 증거가 너무 큰 영향을 미치지 않도록 하기 위함입니다. 대신 정규화된 신경망은 학습 데이터들에서 자주 나타나는 증거 유형들에 반응하도록 학습합니다. 반대로 큰 가중치를 가진 신경망은 입력의 작은 변화에 반응하여 동작이 상당히 많이 변할 수 있습니다. 따라서 정규화되지 않은 신경망은 큰 가중치를 사용하여 학습 데이터의 노이즈에 대한 많은 정보를 담고 있는 복잡한 모델을 학습할 수 있습니다. 간단히 말해서 정규화된 신경망은 학습 데이터에서 자주 보이는 패턴을 기반으로 비교적 간단한 모델을 구축하도록 하며, 학습 데이터의 노이즈의 특이성을 학습하지 않도록 하는 것입니다. 이렇게 함으로써 우리는 우리의 신경망이 주어진 현상에 대한 실제적인 학습을 하도록 하고 학습한 것을 바탕으로 일반화할 수 있도록 희망합니다.
더 간단한 설명을 선호한다는 이 아이디어에 불안함을 느끼는 사람도 있을 수 있습니다. 어떤 사람들은 때때로 이 아이디어를 "오컴의 면도날"이라고 부르며, 이것이 어떤 과학적 지위를 갖는 것처럼 열성을 보이기도 합니다. 하지만 물론 이것은 일반적으로 받아들여지는 과학 원칙은 아닙니다. 더 복잡한 설명보다 간단한 설명을 선호해야하는 선험적인 논리적 이유는 없습니다. 실제로 때로는 더 복잡한 설명이 옳다는 것으로 밝혀진 사례도 많습니다.
더 복합한 설명이 옳다는 것으로 밝혀진 몇몇 사례를 들어보겠습니다. 1940년대 물리학자 마르셀 샤인은 새로운 자연 입자를 발견했다고 발표했습니다. 그가 근무하던 회사인 제너럴 일렉트릭은 환희에 차서 그의 발견을 널리 홍보했습니다. 하지만 물리학자 한스 베테는 회의적이었습니다. 베테는 샤인을 찾아가 샤인이 발견한 새로운 입자의 궤적을 보여주는 사진들을 살펴보았습니다. 샤인은 베터에게 사진들을 계속 보여주었지만, 각 사진마다 베테는 데이터가 폐기되어야 함을 시사하는 어떤 문데를 지적했습니다. 마침내 샤인은 베테에게 좋아 보이는 사진을 보여주었습니다. 배테는 그것이 단지 통계적 우연일 수도 있다고 말했습니다.
샤인: 네, 하지만 당신의 사고방식을 따르더라도 이것이 통계일 확율은 5분의 1입니다.
베테: 하지만 우리는 이미 5장의 사진을 보았습니다.
샤인: 하지만 제 사진에서는 좋은 사진들마다 좋은 그림들 마다 당신은 다른 이론으로 설명하는 반면, 저의 모든 사진을 설명하는 하나의 가설, 즉 그것들이 [새로운 입자]라는 가설을 가지고 있습니다.
베테: 당신의 설명과 제 설명의 유일한 차이점은 당신의 것이 틀렸고 제 것은 모두 옳다는 것입니다. 당신의 단 하나의 설명은 틀렸고 제 여러 설명은 모두 옳습니다.
후속 연구에서는 자연은 베테에 동의했고, 샤인의 입자는 더 이상 존재하지 않는다는 것이 확인되었습니다.
두 번째 예로, 1859년 천문학자 위르뱅 르베리에는 수성의 궤도가 뉴턴의 만유인력 이론이 에측하는 모양과 정확이 일치하지 않는다는 것을 관찰했습니다. 이는 뉴턴 이론에서 아주 작고 미세한 벗어남이었고, 당시 제시된 여러 설명은 뉴턴 이론이 거의 맞지만 아주 미세한 수정이 필요하다는 주장으로 귀결되었습니다. 1916년 아인슈타인은 뉴턴 중력과는 근본적으로 다르고 훨씬 더 복잡한 수학에 기반한 자신의 일반 상대성 이론을 사용하여 그 벗어남을 매우 잘 설명할 수 있음을 보여주었습니다. 그러한 추가적인 복잡성에도 불구하고 오늘날에는 아인슈타인의 설명이 옳고 뉴턴 중력은 수정된 형태까지 포함하여 틀렷다는 것이 받아들여지고 있습니다. 이는 부분적으로 아인슈타인의 이론이 뉴턴 이론으로는 설명하기 어려운 다른 많은 현상을 설명한다는 것을 우리가 이제 알기 때문입니다. 더욱이, 그리고 훨씬 더 인상적인 것은 아인슈타인의 이론이 뉴턴 중력으로는 전혀 예측할 수 없는 여러 현상을 정확하게 예측한다는 것입니다. 하지만 이러한 인상적인 자질들은 초기에는 완전히 명백하지 않았습니다. 단순성만을 기준으로 판단했다면 뉴턴 이론의 수정된 형태가 논쟁의 여지 없이 더 매력적이었을 것입니다.
이러한 이야기에서 얻을 수 있는 교훈은 세 가지입니다. 첫째, 두 설명 중 어떤 것이 진정으로 "더 간단한" 것인지 결정하는 것은 매우 미묘한 작업일 수 있습니다. 둘째, 그러한 판단을 내릴 수 있다하더라도 단순함은 매우 신중하게 사용해야하는 지침입니다. 셋째, 모델의 진정한 시험은 단순성이 아니라 새로운 행동 영역에서 새로운 현상을 얼마나 잘 예측하는가입니다.
주의해서 해야 하는 말이긴 하지만, 정규화된 신경망이 그렇지 않은 신경망보다 일반적으로 더 잘 일반화할 수 있다는 것은 경험적으로 확인할 수 있는 사실입니다. 따라서 이후 논의에서 정규화를 자ㅈ ㅜ사용할 것입니다. 위에서 설명한 이야기는 정규화가 신경망의 일반화를 돕는 이유에 대해 아직 완전히 설득력 있는 이론적 설명을 아무도 개발하지 못한 이유를 전달하기 위해서 장황하게 설명했습니다. 실제로 연구자들은 다양한 정규화 접근 방식을 시도하고, 어떤 방식이 더 잘 작동하는지 비교하고, 서로 다른 접근 방식이 더 좋거나 더 나쁜 이유를 이해하고자 노력하는 논문들을 계속 쓰고 있습니다. 따라서 정규화를 일종의 임시변통으로 볼 수 있습니다. 종종 도움이 되지만, 우리는 정작 무슨 일이 일어나고 있는지에 대한 완전히 만족스러운 체계적인 이해를 갖고 있지 않으며 단지 불완전한 경험적 규칙과 대략적인 지침만 가지고 있습니다.
여기에는 더 깊은 문제들이 있으며, 이는 과학의 핵심에 관련된 문제입니다. 그것은 우리가 어떻게 일반화하는가 문제입니다. 정규화는 우리의 신경망이 더 잘 일반화되도록 돕는 계산적인 마법 지팡이를 제공할 수 있지만, 일반화가 어떻게 작동하는지에 대한 원리적인 이해나 최상의 접근 방식이 무엇인지에 대한 이해는 제공하지 않습니다.
이것은 특히나 분통 터지는 일인데, 왜냐하면 일상생활에서 우리 인간은 엄청나게 일반화를 잘 하기 때문입니다. 아이는 코끼리 그림 몇 장만 보여줘도 다른 코끼리들을 재빨리 인식하는 법을 배웁니다. 물론 가끔은 실수를 할 수도 있죠. 예를 들어 코뿔소를 코끼리로 착각할 수도 있지만, 일반적으로 이 과정은 놀라울 정도로 정확하게 작동합니다. 그러니 우리는 엄청나게 많은 자유 변수를 가진 시스템, 즉 인간의 뇌를 가지고 있습니다. 그리고 그 시스템은 단 한두 장의 학습 이미지만 보고도 다른 이미지들로 일반화하는 법을 배웁니다. 우리의 뇌는 어떤 의미에서 놀라울 정도로 잘 정규화하고 있는 것입니다. 우리는 어떻게 그렇게 할 수 있는 것일까요? 현재로서는 알 수 없습니다. 앞으로 몇 년 안에 인공 신경망에서 정규화를 위한 더 강력한 기술들이 개발될 것이라고 예상합니다. 궁극적으로 그러한 기술들은 신경망이 더 작은 수의 학습 데이터만 가지고도 잘 일반화할 수 있도록 해줄 것입니다.
사실 우리의 신경망은 우리가 선험적으로 예상할 수 있는 것보다 이미 더 잘 일반화하고 있습니다. 100개의 은닉 뉴런을 가진 신경망은 거의 8만개의 파라미터를 가지고 있습니다. 우리의 학습 데이터는 5만개의 이미지만 있습니다. 이는 마치 5만 개의 데이터가 가리키는 점들에 대해 8만 차 다항식을 맞추려는 것과 같습니다. 당연히 우리의 신경망은 끔찍하게 과적합되어야 합니다. 하지만 앞서 보았듯이 그러한 신경망은 실제로 꽤 잘 일반화합니다. 왜 그럴까요? 잘 이해가 되지 않습니다.
"다층 신경망에서 경사 하강법 학습의 역학에는 '자기 정규화' 효과가 있다"고 추측되어 왔습니다. 이는 매우 운이 좋은 일이지만, 왜 그런지는 이해하지 못하고 있다는 점이 다소 불안합니다. 당분간 우리는 실용적인 접근 방식을 채택하여 가능한 한 정규화를 사용하도록 할 것입니다. 우리의 신경망은 그 덕분에 더 나아질 것입니다.
이 섹션을 마무리하면서 앞에서 설명하지 않고 넘어간 세부 사항, 즉 L2 정규화가 편향을 제한하지 않는다는 사실로 돌아가보도록 하겠습니다. 물론 편향을 정규화하도록 정규화 절차를 쉽게 수정할 수 있습니다. 경험적으로 이렇게 해도 결과가 크게 달라지지 않는 경우가 많으므로, 어느 정도까지는 편향을 정규화할지 여부는 단지 관례에 불과합니다. 그러나 큰 편향을 갖는 것이 큰 가중치를 갖는 것과 같은 방식으로 뉴런을 입력에 민감하게 만들지는 않는다는 점에 주목할 가치가 있습니다. 따라서 우리는 큰 편향이 우리 네트워크가 학습 데이터의 노이즈를 학습하도록 허용할까 봐 걱정할 필요가 없습니다. 동시에 큰 편향을 허용하면 신명망 동작에 더 많은 유연성이 부여됩니다. 특히 큰 편향은 뉴런이 포화되는 것을 더 쉽게 만들고 이는 때때로 바람직합니다. 이러한 이유로 우리는 일반적으로 정규화에 편향에 에 관련된 항을 포함시키지 않습니다.
정규화를 위한 다른 기법들
L2 정규화 외에도 많은 정규화 기법들이 있습니다. 사실, 너무 많은 기법들이 개발되어 다 요약할 수 없을 정도입니다. 이 섹션에서는 과적합을 줄이기 위한 세 가지 기법들, L1 정규화, 드롭아웃, 학습 데이터 크기를 인위적으로 늘리는 방법에 대하여 간략히 다루도록 하겠습니다. 앞서 했던 것처럼 이러한 기법들을 깊이 있게 다루지 않을 것입니다. 대신, 주요 아이디어들을 익히고 사용 가능한 다양한 정규화 기법을 이해하는 것에 집중하도록 하겠습니다.
L1 정규화: 이 기법에서는 가중치의 절대값의 합을 추가하여 비용 함수를 정규화합니다.
$\begin{eqnarray} C = C_0 + \frac{\lambda}{n} \sum_w |w|.\tag{95}\end{eqnarray}$
직관적으로 이것은 큰 가중치에 페널티를 주고 신경망이 작은 가중치를 선호하도록 하는 L2 가중치와 유사합니다. 물론 L1 정규화 항은 L2 정규화 항과 같지 않으므로 정확히 같은 동작을 기대할 수는 없습니다. L1 정규화 항을 사용하여 학습된 신경망의 동작은 L2 정규화를 사용하여 학습된 신경망의 동작과 어떻게 다른지 생각해보도록 하겠습니다.
이를 위하여 비용 함수를 편미분해보도록 하겠습니다. 식 (95)를 미분하면 다음과 같은 결과를 얻을 수 있습니다. ($\rm sgn(w)$는 $w$의 부호를 나타내는 함수이며, $w$가 양수이면 +1, 음수이면 -1이 됩니다.)
$\begin{eqnarray} \frac{\partial C}{\partial w} = \frac{\partial C_0}{\partial w} + \frac{\lambda}{n} \, {\rm sgn}(w),\tag{96}\end{eqnarray}$
위 식을 사용하면 역전파를 쉽게 수정하여 L1 정규화를 사용하여 확률적 경사 하강법을 수행할 수 있습니다. L1 정규화된 신경망의 결과 업데이트 규칙은 다음과 같습니다.
$\begin{eqnarray} w \rightarrow w' = w-\frac{\eta \lambda}{n} \mbox{sgn}(w) - \eta \frac{\partial C_0}{\partial w},\tag{97}\end{eqnarray}$
여기에서도 일반적인 경우와 마찬가지로, 원한다면 미니 배치 평균을 이용하여 $\partial C / \partial w$를 추정해볼 수 있습니다. 이를 L2 정규화 업데이트 규칙(식 (93) 참조)와 비교해 보겠습니다.
$\begin{eqnarray} w \rightarrow w' = w\left(1 - \frac{\eta \lambda}{n} \right) - \eta \frac{\partial C_0}{\partial w}.\tag{98}\end{eqnarray}$
두 식 모두에서 정규화의 효과는 가중치를 축소하는 것입니다. 이는 두 종류의 정규화 모두 큰 가중치에 페널티를 준다는 우리의 직관과 일치합니다. 하지만, 가중치가 축소되는 방식이 다릅니다. L1 정규화에서는 가중치가 0을 향해 일정한 양만큼 축소됩니다. L2 정규황서는 가중치가 $w$에 비례하는 양만큼 축소됩니다. 따라서 특정 가중치의 크기가 $|w|$로 클 때, L1 정규화는 L2 정규화보다 훨씬 적게 가중치를 축소합니다. 반대로 $|w|$가 작을 때, L1 정규화는 L2 정규화보다 훨씬 더 많이 가중치를 축소합니다. 결과적으로 L1 정규화는 신경망의 가중치를 상대적으로 적은 수의 중요한 연결에 집중하는 경향이 있는 반면, 다른 가중치는 0으로 향하게 됩니다.
위의 논의에서 한 가지를 간과했는데 $w = 0$일 때, 편미분 $\partial C / \partial w$가 정의되지 않았다는 것입니다. 그 이유는 함수 $w = 0$에서 뾰족한 "모서리"를 가지므로 해당 지점에서 미분 가능하지 않기 때문입니다. 하지만, 괜찮습니다. 우리가 할 일은 $w = 0$일 때, 확률적 경사 하강법에 대한 일반적인 (정규화되지 않은) 규칙을 적용하는 것입니다. 이는 괜찮을 것입니다. 직관적으로 정규화의 효과는 가중치를 축소하는 것이며, 이미 0인 가중치를 축소할 수는 없습니다. 더 정확히 말하면 $\rm sgn(0) = 0$이라는 규칙과 함께 식 (96)과 (97)을 사용할 것입니다. 이는 L1 정규화를 사용하여 확률적 경사 하강법을 수행하는 멋지고 간결한 규칙이 될 수 있습니다.
드롭아웃(Dropout): 드롭아웃은 근본적으로 다른 정규화 기법입니다. L1과 L2 정규화와 달리 드롭아웃은 비용 함수를 수정하지 않습니다. 대신 드롭 아웃에서는 신경망 자체를 수정합니다. 드롭아웃이 어떻게 작동하는지 기본적인 메커니즘을 먼저 설명한 다음, 왜 작동하는지 그리고 결과가 무엇인지 알아보겠습니다.
다음과 같은 신경망을 학습시킨다고 가정해보겠습니다.

특히, 학습을 위한 입력값 $x$와 그에 대응하는 출력값 $y$가 있다고 가정해 보겠습니다. 보통은 신경망을 통해 $x$를 순전파(forward-propagate)시킨 다음, 역전파(back-propagate)하여 기울기에 대한 기여도를 결정하는 방식으로 학습을 진행합니다. 드롭아웃을 사용하면 이 과정을 변경하게 됩니다. 먼저 신경망의 은닉층 뉴런 절반을 무작위로 (그리고 일시적으로) 삭제하는 것을 먼저 수행합니다. 이때, 입력층과 출력층 뉴런은 그대로 둡니다. 이렇게 하면 다음과 같은 형태의 신경망이 됩니다. 일시적으로 삭제된 드롭아웃 뉴런을 흐릿하게 표시했습니다.

수정된 신경망을 통해 입력값 $x$를 순전파시키고, 마찬가지로 수정된 신경망을 통해 결과를 역전파 시킵니다. 미니 배치에 있는 입력값들로 이 과정을 수행한 후, 가중치와 편향을 업데이트 합니다. 그런 다음 드롭아웃된 뉴런을 복원하고, 은닉 뉴런에서 삭제할 뉴런을 무작위로 새로 선택합니다. 그리고, 다른 미니 배치를 선택하여 기울기를 추정하고, 신경망의 가중치와 편향을 업데이트하는 과정을 반복합니다.
이 과정을 반복함으로써 우리 신경망은 가중치와 편향들의 집합을 학습하게 됩니다. 물론, 이 가중치와 편향들은 은닉층 뉴런의 절반이 삭제(dropout)된 조건에서 학습된 것입니다. 실제로 전체 신경망을 실행할 때 이는 활성화될 은닉층 뉴런이 두 배 많다는 의미입니다. 이를 보상하기 위해 은닉층 뉴런에서 나가는 가중치를 절반으로 줄입니다.
방금 설명한 드롭아웃의 절차는 이상하고 임시방편처럼 이해될 것입니다. 왜 이것이 정규화에 도움이 될 것이라고 기대할 수 있을까요? 무슨 일이 일어나고 있는지 설명하기 위해 잠시 다롭아웃에 대한 생각을 멈추고 대신 표준 방식(드롭아웃이 없는 상태)로 신경망을 훈련시키는 것을 상상해보시기 바랍니다. 특히, 같은 학습 데이터를 사용하여 여러 개의 서로 다른 신경망을 학습시키고 있다고 상상해보세요. 물론, 신경망이 처음부터 동일하지 않을 수 있으며, 결과적으로 학습 후 때로는 다른 결과를 도출할 수도 있습니다. 그런 일이 발생하면 어떤 종류의 평균화 또는 투표 방식을 사용하여 어떤 출력을 수락할지 결정할 수 있습니다. 예를 들어, 다섯 개의 네트워크를 훈련했고 그 중에 세 개가 숫자를 "3"으로 분류했다면 그것은 아마도 실제로 "3"일 것입니다. 다른 두 신경망은 아마도 실수를 하고 있는 것입니다. 이러한 종류의 이러한 종류의 평균화 방식은 종종 과적합을 줄이는 강력한 (그러나 비용이 많이 드는) 방법으로 여겨집니다. 이유는 서로 다른 신경망이 서로 다른 방식으로 과적합될 수 있으며, 평균화가 그러한 종류의 과접합을 제거하는데 도움이 될 수 있기 때문입니다.
이것이 드롭아웃과 무슨 관련이 있을까요? 경험적으로 볼 때, 서로 다른 뉴런 집합을 드롭아웃시키는 것은 마치 서로 다른 신경망을 훈련시키는 것과 같습니다. 따라서 드롭아웃 절차는 매우 많은 수의 서로 다른 신경망의 효과를 평균화하는 것과 같습니다. 서로 다른 신경망은 서로 다른 방식으로 과적합될 것이므로 희망적으로 드롭아웃의 순효과는 과적합을 줄이는 것입니다.
드롭아웃에 대한 이와 관련된 경험적 설명은 이 기술을 사용한 가장 초기 논문 중 하나에 제시되어 있습니다. 이 기법은 뉴런이 특정 다른 뉴런의 존재에 의존할 수 없기 때문에 뉴런들의 복잡한 공동 적응을 줄여줍니다. 따라서, 각 뉴런은 많은 다른 무작위 뉴런 부분 집합과 함께 사용될 수 있는 더 강력한 특징을 학습하게 됩니다. 다시 말해, 우리 신경망을 예측을 수행하는 모델로 본다면, 드롭아웃응ㄴ 모델이 어떤 개별 증거가 사라지더라도 견고하게 작동하도록 보장하는 방법으로 생각할 수 있습니다. 이는 가중치를 줄여 신경망의 개별 연결이 끊어지더라도 더 강력하게 만드는 경향이 있는 L1 및 L2 정규화와 다소 유사합니다.
물론 드롭아웃의 진정한 가치는 신경망의 성능을 향상시키는 데 매우 성공적이었다는 점입니다. 이 기법을 처음 소개한 논문에서는 여러 가지 다른 작업에 적용했습니다. 우리에게 특히 흥미로운 점은 그들이 우리가 고려해 온 것과 유사한 방식으로 일반적인 피드포워드 신경망을 사용하여 MNIST 숫자 분류에 드롭아웃을 적용했다는 것입니다. 이 논문에서는 당시 그러한 아키텍처를 사용하여 달성한 최고 결과가 테스트 데이터에서 98.4%의 분류 정확도였다고 언급하고 있습니다. 마찬가지로 이미지 및 음성 인식, 자연어 처리 분야의 문제를 포함한 다른 많은 작업에서도 놀라운 성과가 이어졌습니다. 드롭아웃은 특히 과적합 문제가 자주 발생하는 대규모 심층 신경망을 학습시키는데 매우 유용합니다.
학습 데이터를 인위적으로 확장하기: 앞서 1,000개의 학습 이미지만 사용했을 때, MNIST 분류 정확도가 80% 중반까지 떨어지는 것을 확인했습니다. 학습 데이터가 적다는 것은 우리 신경망이 사람이 쓴 숫자를 쓰는 다양한 방식에 더 적게 노출된다는 의미이므로 이는 당연한 결과입니다. 다양한 숫자의 학습 데이터를 사용하여 30개의 은닉 뉴런을 가진 신경망을 학습시키고, 성능이 어떻게 달라지는지 살펴보겠습니다. 미니 패치 크기 10, 학습률 $\eta = 0.5$, 정규화 파라미터 $\lambda = 5.0$, 그리고 교차 엔트로피 비용 함수를 사용하여 학습시키도록 하겠습니다. 전체 학습 데이터를 사용할 때는 30 에포크 동안 학습을 진행하고, 더 작은 훈련 데이터를 사용할 때는 에포크 수를 비례적으로 늘려가도록 하겠습니다. 가중치 감수 비율이 모든 학습들에서 동일하게 유지되도록 하기 위해서 전체 학습 데이터를 사용할 때는 정규화 파리미터를 $\lambda = 5.0$을 사용하고 더 작은 훈련 데이터를 사용할 때는 $\lambda$를 비례적으로 줄이겠습니다.

보시다시피, 더 많은 학습 데이터를 사용할수록 분류 정확도가 상당히 향상됩니다. 더 많은 데이터가 있다면 더 높은 학습 정확도를 얻을 수 있습니다. 물론, 위 그래프를 보면 포화 상태에 거의 도달한 것처럼 보입니다. 그러나, 학습 데이터의 크기를 로그 스케일로 표시하여 그래프를 다시 그려보겠습니다.

그래프가 끝까지 계속 상승하고 있는 것이 분명해 보입니다. 이는 만약 우리가 훨씬 더 많은 학습 데이터, 예를 들어 5만개가 아닌 수백만 또는 수십억 개의 손글씨 샘플을 사용한다면, 이는 매우 작은 네트워크에서도 훨씬 더 나은 성능을 얻을 수 있을 가능성이 높다는 것을 시사합니다.
더 많은 학습 데이터를 얻는 것은 좋은 생각입니다. 불행히도 이는 비용이 많이 들 수도 있고, 실제로 항상 가능한 것은 아닙니다. 따라서, 학습 데이터를 인위적으로 확장하는 것이 더 효과적일 수 있습니다. 예를 들어, MNIST의 학습 데이터에서 숫자 5를 생각해봅시다.


이러한 아이디어는 매우 효과적이어서 널리 사용되었습니다. 이 아이디어의 여러 변형을 MNIST에 적용한 논문의 일부 결과를 살펴보겠습니다. 이들이 고려한 신경망 아키텍쳐 중 하나는 우리가 사용해 온 것과 유사한 방식으로 800개의 은닉 뉴런을 가진 순방향 신경망이었으며 교차 엔트로피 비용함수를 사용했습니다. 표준 MNIST 학습 데이터를 사용하여 신경망을 학습시킨 결과 테스트 데이터를 가지고 98.4%의 분류 정확도를 달성했습니다. 그러나 그들은 위에서 설명한 대로 회전뿐만 아니라 이미지를 평행 이동시키기도 하고, 기울여서 학습 데이터를 확장했습니다. 확장된 데이터를 가지고 학습한 결과 신경망의 정확도를 98.9%까지 높였습니다. 또한 그들은 "탄성 왜곡"이라고 부르는 손 근육에서 발견되는 무작위 진동을 모방하기 위한 특별한 유형의 이미지 왜곡도 실험했습니다. 탄성 왜곡을 사용하여 데이터를 확장함으로써 그들은 훨씬 더 높은 정확도인 99.3%를 달성하기도 했습니다. 효과적으로 그들은 실제 손글씨에서 발견되는 종류의 변화에 신경망을 노출시켜 신경망의 경험을 넓히고 있었습니다.
이러한 아이디어를 변형하여 손글씨 인식뿐만 아니라 많은 학습의 성능을 향상시키는데 사용될 수 있습니다. 일반적인 원칙은 실제 세계의 변화를 반영하는 연산을 적용하여 학습 데이터를 확장하는 것입니다. 이를 수행하는 방법을 생각하는 것은 어렵지 않습니다. 예를 들어 음성인식을 수행하는 신경망을 구축한다고 가정해봅시다. 우리 인간은 배경소음과 같은 왜곡이 있는 경우에도 음성을 인식할 수 있습니다. 따라서 배경 소음을 추가하여 데이터를 확장할 수 있습니다. 또한 음성이 빨라지거나 느려지더라도 음성을 인식할 수 있습니다. 예를 들어, 소음을 추가하여 학습 데이터를 확장하는 대신, 먼저 소음 감소 필터를 적용하여 신경명에 대한 입력을 정리하는 것이 훨씬 더 효율적일 수 있습니다. 그럼에도 불구하고 학습 데이터를 확장한다는 아이디어에를 염두에 두고 이를 적용할 기회를 찾는 것이 중요합니다.
큰 데이터와 분류 정확도 비교의 의미에 대한 여담: 우리 신경망의 정확도가 학습 데이터 크기에 따라 어떻게 변하는지 다시 살펴보겠습니다.

신경마 대신 다른 기계 학습 기술을 이용하여 숫자를 분류한다고 가정해 보겠습니다. 예를 들어 1장에서 간략하게 살펴보았던 서포트 벡터 머신(SVM)을 사용해보겠습니다. 1장에서와 마찬가지로 SVM에 익숙하지 않더라도 걱정할 필요는 없습니다. 자세한 내용을 이해할 필요는 없습니다. 대신 scikit-learn 라이브러리에서 제공하는 SVM을 사용하도록 하겠습니다. 다음은 학습 데이터 크기의 함수로 SVM 성능이 어떻게 달라지는지를 보여주는 그래프입니다. 비교하기 쉽도록 신경망의 결과도 함께 표시했습니다.

아마 이 그래프에서 가장 먼저 눈에 띄는 점은 우리 신경망이 모든 학습 데이터 크기를 가지고도 SVM보다 성능이 뛰어나다는 것입니다. 물론 좋은 일이지만, scikit-learn의 SVM 기본설정을 그대로 사용했고 우리 신경망은 개선하기 위해 상당한 작업을 거쳤기 때문에, 이에 너무 고무될 필요는 없습니다. 그래프에 대한 더 미묘하지만 더 흥미로운 사실은 5만개의 이미지를 사용하여 SVM을 훈련하면 5천개의 이미지를 사용하여 훈련한 우리 신경망(93.24% 정확도)보다 실제로 더 나은 성능(94.48% 정확도)을 보인다는 것입니다. 즉, 더 많은 학습 데이터는 때때로 사용된 기계 학습 알고리즘의 차이를 보상할 수 있습니다.
훨씬더 흥미로운 것도 있습니다. 알고리즘 A와 알고리즘 B라는 두 기계 학습 알고리즘을 사용하여 문제를 해결하려고 한다고 가정해보겠습니다. 때로는 알고리즘 A가 특정 집합의 학습 데이터에서는 알고리즘 B보다 성능이 뛰어나지만, 다른 집합의 학습 데이터에서는 그 반대일 수 있습니다. 위에서 그런 현상을 볼 수는 없습니다. 두 그래프가 교차하는 지점이 없습니다. 하지만 실제로 이런 일은 종종 발생합니다. "알고리즘 A가 알고리즘 B보다 더 나은가요?"라는 질문에 대한 올바른 답변은 실제로 "어떤 학습데이터를 사용하고 있습니까?"입니다.
이 모든 것은 개발할 때는 물론 연구 논문을 읽을 때 모두 염두에 두어야할 주의 사항입니다. 많은 논문이 표준 벤치마크 데이터 세트에서 성능을 향상시키기 위해 개로운 기술을 찾는데 초점을 맞춥니다. "우리는 놀라운 기술이 표준 벤치마크 Y에서 X 퍼센트의 성능 향상을 가져왔습니다."는 연구 주장의 대표적인 형태입니다. 이러한 주장은 종종 정말 흥미롭지만, 사용된 특정 학습 데이터 집합에서만 적용된다는 점을 이해해야 합니다. 벤치마크 데이터 세트를 처음 만든 사람들이 더 많은 연구비를 받았던 다른 역사를 상상해보세요. 그들은 추가 자금을 사용하여 더 많은 학습 데이터를 수집했을 수도 있습니다. 놀라운 기술로 인한 "향상"이 더 큰 학습 데이터 집합에서 사라질 가능성도 있습니다. 즉, 개선했다는 주장은 단순히 역사의 우연일 수도 있습니다. 특히, 실제 응용 분야에서 얻을 수 있는 메시지는 더 나은 알고리즘과 더 나은 학습 데이터가 모두 필요하다는 것입니다. 더 나은 알고리즘을 찾는 것은 좋지만, 더 많거나 더 나은 학습 데이터를 얻는 것이 더 쉬운 방법임을 간과한 채 더 나은 알고리즘을 찾는데만 집중하고 있지 않는지를 되돌아 보시기 바랍니다.
요약: 이제 과적합과 정규화에 대한 심층적인 탐구를 마무리하겠습니다. 물론 이 문제는 다시 한번 더 다룰 예정입니다. 여러 번 언급했듯이, 과적합은 신경망에서 특히 컴퓨터 성능이 향상되고 더 큰 신경망을 학습시킬 수 있게 되면서 주요한 문제가 되었습니다. 그 결과 과적합을 줄이기 위해 강력한 정규화 기술을 개발해야 할 필요성이 커졌으며, 이는 현재 매우 활발히 연구되는 분야입니다.
가중치 초기화
신경망을 만들 때 초기 가중치와 편향을 어떻게 설정해야하는지 결정해야합니다. 지금까지 1장에서 간략하게 설명한 방식에 따라 우리는 이를 설정해왔습니다. 다시 한번 말씀드리자면, 그 방식은 평균이 -이고 표준편차가 1인 정규화된 독립적인 무작위 변수를 사용하여 가중치와 편향을 모두 선택하는 것이었습니다. 이 접근 방식은 잘 작동했지만, 다소 임시 방편적이었고, 초기 가중치와 편향을 설정하는 더 나은 방법을 찾아 신경망이 더 빨리 학습하도록 도울 수 있는지 다시 살펴볼 가치가 있습니다.
정규화된 가우시안 분포로 초기화하는 것보다 훨씬 더 잘할 수 있다는 것이 밝혀졌습니다. 이유를 알아보기 위해 많은 수의 입력 뉴런(예: 1,000개)을 가진 신경망으로 작업을 한다고 가정해보겠습니다. 그리고 첫 번째 은닉층에 연결되는 가중치를 초기화하기 위해 정규화된 가우시안 분포를 사용했다고 가정해보겠습니다. 지금은 입력 뉴런을 은닉층 첫 번째 뉴런에 연결하는 가중치에만 집중하고 그 나머지는 무시하도록 하겠습니다.

간단하게 가정을 하나 해보도록 하겠습니다. 절반의 입력 뉴련이 켜져(즉, 1로 설정) 있고, 나머지 절반의 입력 뉴런은 꺼져(즉, 0으로 설정) 있는 학습 데이터 $x$를 사용하여 학습을 시도한다고 가정해 봅시다. 이어지는 논의는 더 일반적인 경우를 가지고도 가능하지만, 이 특별한 경우를 통해서 요점을 더 쉽게 파악할 수 있을 것입니다. 이제 은닉 뉴런으로 들어오는 입력의 가중치 합 $z = \Sigma _j w_jx_j + b$를 고려해 봅시다. 여기서 500개 항의 입력 $x_j$가 0이기 때문에 이들의 합은 사라집니다. 따라서 $z$는 총 501개의 정규돠된 가우시안 확율 변수의 합이 되는데, 이는 500개의 가중치 항과 1개의 추가 편향 항을 고려한 것입니다. 따라서 $z$ 자체는 평균이 0이고 표춘 편차가 $\sqrt{501} \approx 22.4$인 가우시안 분표를 따릅니다. 즉,. $z$는 뾰족하지 않은 매우 넓은 아래와 같은 가우시안 분포를 가집니다.

특히 이 그래프에서 $|z|$가 꽤 클 가능성이 높다는 것을 알 수 있습니다. 즉, $z \gg 1$이거나 $z \ll -1$일 가능성이 큽니다. 이 경우 은닉 뉴런의 출력 $\sigma (z)$는 1 또는 0에 매우 가까워질 것입니다. 이는 은닉 뉴런이 포화되었다는 의미입니다. 그리고 아시다시피 이러한 상황이 발생하면 가중치에 작은 변화를 주어도 은닉 뉴런의 활성화에 아주 미미한 변화만 일어납니다. 은닉 뉴런의 이러한 미미한 활성화 변화는 결국 네트워크의 나머지 뉴런에 거의 영향을 미치지 않으며, 비용 함수에도 그에 상응하는 아주 미미한 변화만 관찰될 것입니다. 결과적으로 경사 하강법 알고리즘을 사용할 때 이러한 가중치는 매우 느리게 학습될 것입니다. 이는 이전 장에서 잘못된 값으로 포화된 출력 뉴런 때문에 학습 속도가 느려졌던 문제와 유사합니다. 우리는 이전 문제를 비용 함수를 현명하게 선택하여 해결했습니다. 불행이도, 그것이 포화된 출력 뉴런에는 도움이 되었지만, 포화된 은닉 뉴런 문제에는 전혀 도움이 되지 않습니다.
우리는 첫 번째 은닉층에 입력되는 가중치에 대하여 이야기했습니다. 물론, 유사한 논의는 후속 은닉층에도 적용됩니다. 만약 후속 은닉층의 가중치가 정규화된 가우시안 분포를 사용하여 초기화된다면 활성화 값은 종종 0또는 1에 매우 가까워지고 학습은 매우 느리게 진행될 것입니다.
이러한 포화를 방지하고 학습 속도 저하를 피하기 위해 가중치와 편향을 더 잘 초기화할 수 있는 방법이 있을까요? $n_{in}$개의 입력 가중치를 가진 뉴런이 있다고 가정해봅시다. 그러면 이러한 가중치를 평균이 0이고 표준 편차가 $1 / \sqrt {n_{in}}$인 가우시안 확률 변수로 초기화할 것입니다. 즉, 가우시안 분포를 더 좊게 만들어 뉴런이 포화될 가능성을 줄일 것입니다. 편향은 잠시 후에 다시 설명할 것이므로 지금은 평균이 0이고 표준 편차가 1인 가우시안 분포를 따른다고 간주하겠습니다. 이러하다면 가중치 합 $z = \Sigma_j w_jx_j + b$는 평균이 0인 가우시안 확률 변수가 되겠지만, 이전보다 훨씬 더 뾰족한 형태를 가질 것입니다. 이전과 마찬가지로 입력의 500개는 0이고 나머지 500개는 1이라고 가정해 봅시다. 그러면 $z$가 평균이 0이고 표준 편차가 $\sqrt {3/2} = 1.22...$인 가우시안 분포를 따른다는 것을 쉽게 알 수 있습니다. 이는 이전보다 훨썬 더 뾰족한 형태입니다.

이러한 뉴런은 훨씬 포화될 가능성이 낮으며, 따라서 학습 속도 저하 문제가 발생할 가능성도 훨씬 적습니다.
위에서 편향은 이전과 같이 평균이 0이고 표준 편차가 1인 가우시안 확률 변수로 초기화될 것이라고 언급했습니다. 이렇게 해도 괜찮습니다. 왜냐하면 이렇게 한다고 해서 뉴런이 포화될 가능성이 크게 높아지지는 않기 때문입니다. 사실 포화 문제만 피할 수 있다면 편향을 어떻게 초기화하는지는 그다지 중요하지 않습니다. 어떤 사람들은 심지어 모든 편향을 0으로 초기화하고 경사 하강법을 통해 적절한 편향을 학습하도록 합니다. 하지만 큰 차이를 만들 가능성은 적으므로 이전과 동일한 초기화 절차를 계속 유지하도록 하겠습니다.
가중치 초기화에 대한 기존 방식과 새로운 방식 모두의 결과를 MNIST 숫자 분류 작업을 사용하여 비교해보겠습니다. 이전과 마찬가지로 30개의 은닉 뉴런, 미니 배치 크기 10, 정규화 파라미터 $\lambda = 5.0$, 교차 엔트로피 비용 함수를 사용하겠습니다. 학습률 $\eta = 0.5$에서 0.1로 약간 줄여보겠습니다. 그래프에서 그 결과를 조금 더 쉽게 볼 수 있기 위함입니다. 이전의 가중치 초기화 방법으로 학습시킬 수 있습니다.
>>> import mnist_loader >>> training_data, validation_data, test_data = \ ... mnist_loader.load_data_wrapper() >>> import network2 >>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost) >>> net.large_weight_initializer() >>> net.SGD(training_data, 30, 10, 0.1, lmbda = 5.0, ... evaluation_data=validation_data, ... monitor_evaluation_accuracy=True)
새로운 가중치 초기화 방법을 사용하여 학습을 진행할 수 있습니다. 이는 실제로 훨씬 더 간단합니다. network2에서 가중치를 초기화하는 기본 방식이 이 새로운 방식을 사용하기 때문입니다. 즉 위의 net.large_weight_initialization() 호출을 생략하기만 하면됩니다.
(주석: net.large_weight_initialization()을 생략하면 조정된 가중치 초기화가 이미 적용된 net.default_weight_initialization()가 호출된다.)
>>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost) >>> net.SGD(training_data, 30, 10, 0.1, lmbda = 5.0, ... evaluation_data=validation_data, ... monitor_evaluation_accuracy=True)
* 주석: 앞서 run4.py를 조금 변경하면 위의 실행은 가능하므로 실행코드는 생략합니다.
이를 실행한 결과를 그래프로 그려보면 아래와 같습니다.

두 경우 모두 결국 96%를 약간 넘는 분류 정확도를 보입니다. 두 경우 모두의 최종적인 분류 정확도는 거의 같아진다는 것을 알 수 있습니다. 그러나 새로운 초기화 기술은 훨씬 더 빠르게 목표에 도달하게 해 줍니다. 첫 번째 에포크의 학습이 끝날 때, 기존의 가중치 초기화 방식은 87% 미만의 분류 정확도를 보인 반면, 새로운 방식은 이미 거의 93%에 도달했습니다. 이런 것이 가능한 이유는 새로운 가중치 초기화 방식이 훨씬 더 나은 조건에서 시작하도록 도와주어 더 빠르게 좋은 결과를 얻을 수 있다는 것입니다. 100개의 은닉 뉴런을 사용하여 결과를 그래프로 그려보아도 동일한 현상이 일어납니다.

이 경우는 두 경우의 분류 정확도가 같아지지 않습니다. 하지만, 몇 번의 학습을 더 거치면 정확도가 거의 같아지긴 합니다. 따라서, 이러한 실험 결과를 바탕으로 개선된 가중치 초기화는 학습 속도만 높일 뿐 신경망의 최종 성능은 변화시키지 않는 것처럼 보입니다. 하지만 4장에서 $1 / \sqrt{n_{in}}$ 가중치 초기화를 사용했을 때 장기적인 동작이 훨씬 더 나은 신경망의 예시에 대하여 다루도록 하겠습니다. 따라서 학습 속도뿐만 아니라 때로는 최종 성능도 향상될 수 있습니다.
$1 / \sqrt {n_{in}}$ 가중치 초기화 방식은 신경망 학습 방식을 개선하는 데 도움이 됩니다. 이 기본적인 아이디어를 바탕으로 다른 여러 가지 가중치 초기화 기술도 제안되었습니다. $1 / \sqrt {n_{in}}$ 방식이 우리의 목적에 충분히 부합하므로 여기에서는 다른 접근 방식들을 다루지는 않겠습니다. 더 자세히 알고 싶은 분은 2012년 Yoshua Bengio의 논문의 14페이지와 15페이지에 있는 논의와 거기에 있는 참고 문헌들을 살펴보시기 바랍니다.
손글씨 인식에 대한 재고찰: 코드
이 장에서 논의한 내용들을 코드로 구현해보도록 하겠습니다. 1장에서 개발한 프로그램 network.py의 개선된 버전인 network2.py를 개발할 것입니다. 오랫동안 network.py를 살펴보지 않았다면 이전의 논의들을 빠르게 읽어보는 것이 도움이 될 수 있습니다. 코드는 74줄에 불과하여 쉽게 이해할 수 있습니다.
network.py에서와 마찬가지로 network2.py의 핵심은 신경망을 나타내는데 사용하는 Network 클래스입니다. Network 클래스의 인스턴스는 신경망의 각 계층의 크기 정보인 sizes와 사용할 비용 함수인 cost를 선택적으로 지정하여 초기화할 수 있습니다. 비용 함수는 기본적으로 교차 엔트로피로 설정됩니다.
class Network(object): def __init__(self, sizes, cost=CrossEntropyCost): self.num_layers = len(sizes) self.sizes = sizes self.default_weight_initializer() self.cost=cost
__init__ 매서드의 처음 두 줄은 network.py와 동일하며, 자명합니다. 하지만 다음 두 줄은 새로운 내용이며, 이것들이 무엇을 하는지 자세히 이해할 필요가 있습니다.
먼저 default_weight_initializer 매서드를 살펴보겠습니다. 이 메서드는 가중치 초기화에 대한 새롭고 개선된 접근 방식을 사용합니다. 앞서 보았듯이 이 방식에서 뉴런으로 들어오는 가중치는 평균이 0이고 표준 편차가 뉴런으로 들어오는 연결 수의 제급근으로 나눈 값인 가우시안 확률 변수로 초기화 됩니다. 또한 이 메서드에서는 편향도 평균이 0이고 표준 편차가 1인 가우시안 확률 변수를 사용하여 최고화합니다. 다음은 그 코드입니다.
def default_weight_initializer(self): self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]] self.weights = [np.random.randn(y, x)/np.sqrt(x) for x, y in zip(self.sizes[:-1], self.sizes[1:])]
이 코드를 이해하는데 선형 대수를 수행하기 위한 Numpy 라이브러리인 np를 떠올리는 것도 도움이 될 것입니다. 프로그램의 시작 부분에서 Numpy를 import할 것입니다. 또한 첫 번째 계층의 뉴런에 대해서는 편향을 초기화하지 않는다는 점에 유의하십시오. 첫 번재 계층은 입력 계층이므로 편향이 사용되지 않기 때문입니다. network.py에서도 마찬가지였습니다.
default_weight_initializer를 보완하기 위해 large_weight_initializer 메서드도 포함할 것입니다. 이 매서드는 1장의 이전 방식을 사용하여 가중치와 편향을 초기화하며, 가중치와 편향 모두 평균이 0이고 표준 편차가 1인 가우시안 확률 변수로 초기화됩니다. 물론 코드는 default_weight_initializer와 크게 다르지 않습니다.
def large_weight_initializer(self): self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]] self.weights = [np.random.randn(y, x) for x, y in zip(self.sizes[:-1], self.sizes[1:])]
large_weight_initializer 메서드는 주로 이번 장의 결과를 1장의 결과와 더 쉽게 비교할 수 있도록 포함시켰습니다. 실제로 이 메서드를 사용하는 것을 추천하지 않습니다.
Network 클래서의 __init__ 메서드에서 두 번째 새로운 점은 이제 cost 속성을 초기화한다는 것입니다. 이것이 어떻게 작동하는지 이해하기 위해 교차 엔트로피 비용을 나타내는데 사용하는 클래스를 살펴보겠습니다.
class CrossEntropyCost(object): @staticmethod def fn(a, y): return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a))) @staticmethod def delta(z, a, y): return (a-y)
위 함수를 조금 자세히 살펴보겠습니다. 먼저 살펴볼 점은, 수학적으로 볼 때 교차 엔트로피는 함수지만, 우리는 파이선 함수가 아닌 파이선 클래스로 구현했다는 점입니다. 왜 그런 선택을 했을까요? 그 이유는 비용 함수가 우리 신경망에서 두 가지 다른 역할을 하기 때문입니다. 명백한 역할은 출력 활성화 값 $a$가 원하는 출력 값 $y$와 얼마나 잘 일치하는지 측정하는 척도라는 것입니다. 이 역할은 CrossEntropyCost.fn 메서드에 의해 수행됩니다. (참고로, CrossEntropyCost.fn 내부의 np.nan_to_num 호출은 Numpy가 0에 매우 가까운 수의 로그를 정확하게 처리되도록 보장합니다.) 그러나 비용 함수가 우리 신경망에 들어가는 두 번째 방식도 있습니다. 2장에서 역전파 알고리즘을 실행할 때 신경망의 출력 오류 $\delta ^L$을 계산해야 한다는 것을 상기해 보십시오. 출력 오류의 형태는 비용 함수 선택에 따라 달라집니다. 즉, 비용 함수가 다르면 출력 오류의 형태도 달라집니다. 교차 엔트로피의 경우 출력 오류는 식 (66)에서 보았듯이 다음과 같습니다.
$\begin{eqnarray} \delta^L = a^L-y.\tag{99}\end{eqnarray}$
이러한 이유로 신경망 출력 오류를 계산하는 방법을 알려주는 두 번째 메서드인 CrossEntropyCost.delta 를 정의합니다. 그리고 이 두 메서드를 신경망이 비용 함수에 대해 알아야할 모든 것을 담고 있는 하나의 클래스로 묶습니다.
비슷한 방식으로 network2.py에는 이차 비용 함수를 나타내는 클래스도 포함되어 있습니다. 이는 1장의 결과와 비교하기 위해 포함되었으며, 앞으로는 주로 교차 엔트리피를 사용할 것입니다. 코드는 바로 아래에 있습니다. QuadraticCost.fn 메서드는 실제 출력 $a$와 원하는 출력 $y$에 연관된 이차 비용을 직접 계산합니다. QuadraticCost.delta가 반환하는 값은 2장에서 도출한 이차 비용에 대한 출력 오류 식(30)을 기반으로 합니다.
class QuadraticCost(object): @staticmethod def fn(a, y): return 0.5*np.linalg.norm(a-y)**2 @staticmethod def delta(z, a, y): return (a-y) * sigmoid_prime(z)
이제 network2.py와 network.py의 주요 차이점을 이해했습니다. 모든 것이 꽤 간단합니다. L2 정규화 구현을 포함하여 몇 가지 더 변경 사항이 있으며, 아래에서 설명하겠습니다. 그 전에 network2.py의 전체 코드를 살펴보겠습니다. 모든 코드를 자세히 읽을 필요는 없지만 프로그램의 전반적인 구조를 이해하고 특히 프로그램에 포함된 주석들을 읽어 각 부분이 무엇을 이해하는 것이 좋습니다. 물론 원하는 만큼 깊이 파고 들수도 있습니다. 길을 잃으면 아래 설명을 계속 읽고 나중에 코드로 돌아가는 것이 좋을 수도 있습니다. 어쨌든 코드는 아래와 같습니다.
"""network2.py ~~~~~~~~~~~~~~ An improved version of network.py, implementing the stochastic gradient descent learning algorithm for a feedforward neural network. Improvements include the addition of the cross-entropy cost function, regularization, and better initialization of network weights. Note that I have focused on making the code simple, easily readable, and easily modifiable. It is not optimized, and omits many desirable features. """ #### Libraries # Standard library import json import random import sys # Third-party libraries import numpy as np #### Define the quadratic and cross-entropy cost functions class QuadraticCost(object): @staticmethod def fn(a, y): """Return the cost associated with an output ``a`` and desired output ``y``. """ return 0.5*np.linalg.norm(a-y)**2 @staticmethod def delta(z, a, y): """Return the error delta from the output layer.""" return (a-y) * sigmoid_prime(z) class CrossEntropyCost(object): @staticmethod def fn(a, y): """Return the cost associated with an output ``a`` and desired output ``y``. Note that np.nan_to_num is used to ensure numerical stability. In particular, if both ``a`` and ``y`` have a 1.0 in the same slot, then the expression (1-y)*np.log(1-a) returns nan. The np.nan_to_num ensures that that is converted to the correct value (0.0). """ return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a))) @staticmethod def delta(z, a, y): """Return the error delta from the output layer. Note that the parameter ``z`` is not used by the method. It is included in the method's parameters in order to make the interface consistent with the delta method for other cost classes. """ return (a-y) #### Main Network class class Network(object): def __init__(self, sizes, cost=CrossEntropyCost): """The list ``sizes`` contains the number of neurons in the respective layers of the network. For example, if the list was [2, 3, 1] then it would be a three-layer network, with the first layer containing 2 neurons, the second layer 3 neurons, and the third layer 1 neuron. The biases and weights for the network are initialized randomly, using ``self.default_weight_initializer`` (see docstring for that method). """ self.num_layers = len(sizes) self.sizes = sizes self.default_weight_initializer() self.cost=cost def default_weight_initializer(self): """Initialize each weight using a Gaussian distribution with mean 0 and standard deviation 1 over the square root of the number of weights connecting to the same neuron. Initialize the biases using a Gaussian distribution with mean 0 and standard deviation 1. Note that the first layer is assumed to be an input layer, and by convention we won't set any biases for those neurons, since biases are only ever used in computing the outputs from later layers. """ self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]] self.weights = [np.random.randn(y, x)/np.sqrt(x) for x, y in zip(self.sizes[:-1], self.sizes[1:])] def large_weight_initializer(self): """Initialize the weights using a Gaussian distribution with mean 0 and standard deviation 1. Initialize the biases using a Gaussian distribution with mean 0 and standard deviation 1. Note that the first layer is assumed to be an input layer, and by convention we won't set any biases for those neurons, since biases are only ever used in computing the outputs from later layers. This weight and bias initializer uses the same approach as in Chapter 1, and is included for purposes of comparison. It will usually be better to use the default weight initializer instead. """ self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]] self.weights = [np.random.randn(y, x) for x, y in zip(self.sizes[:-1], self.sizes[1:])] def feedforward(self, a): """Return the output of the network if ``a`` is input.""" for b, w in zip(self.biases, self.weights): a = sigmoid(np.dot(w, a)+b) return a def SGD(self, training_data, epochs, mini_batch_size, eta, lmbda = 0.0, evaluation_data=None, monitor_evaluation_cost=False, monitor_evaluation_accuracy=False, monitor_training_cost=False, monitor_training_accuracy=False): """Train the neural network using mini-batch stochastic gradient descent. The ``training_data`` is a list of tuples ``(x, y)`` representing the training inputs and the desired outputs. The other non-optional parameters are self-explanatory, as is the regularization parameter ``lmbda``. The method also accepts ``evaluation_data``, usually either the validation or test data. We can monitor the cost and accuracy on either the evaluation data or the training data, by setting the appropriate flags. The method returns a tuple containing four lists: the (per-epoch) costs on the evaluation data, the accuracies on the evaluation data, the costs on the training data, and the accuracies on the training data. All values are evaluated at the end of each training epoch. So, for example, if we train for 30 epochs, then the first element of the tuple will be a 30-element list containing the cost on the evaluation data at the end of each epoch. Note that the lists are empty if the corresponding flag is not set. """ if evaluation_data: n_data = len(evaluation_data) n = len(training_data) evaluation_cost, evaluation_accuracy = [], [] training_cost, training_accuracy = [], [] for j in xrange(epochs): random.shuffle(training_data) mini_batches = [ training_data[k:k+mini_batch_size] for k in xrange(0, n, mini_batch_size)] for mini_batch in mini_batches: self.update_mini_batch( mini_batch, eta, lmbda, len(training_data)) print "Epoch %s training complete" % j if monitor_training_cost: cost = self.total_cost(training_data, lmbda) training_cost.append(cost) print "Cost on training data: {}".format(cost) if monitor_training_accuracy: accuracy = self.accuracy(training_data, convert=True) training_accuracy.append(accuracy) print "Accuracy on training data: {} / {}".format( accuracy, n) if monitor_evaluation_cost: cost = self.total_cost(evaluation_data, lmbda, convert=True) evaluation_cost.append(cost) print "Cost on evaluation data: {}".format(cost) if monitor_evaluation_accuracy: accuracy = self.accuracy(evaluation_data) evaluation_accuracy.append(accuracy) print "Accuracy on evaluation data: {} / {}".format( self.accuracy(evaluation_data), n_data) print return evaluation_cost, evaluation_accuracy, \ training_cost, training_accuracy def update_mini_batch(self, mini_batch, eta, lmbda, n): """Update the network's weights and biases by applying gradient descent using backpropagation to a single mini batch. The ``mini_batch`` is a list of tuples ``(x, y)``, ``eta`` is the learning rate, ``lmbda`` is the regularization parameter, and ``n`` is the total size of the training data set. """ nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] for x, y in mini_batch: delta_nabla_b, delta_nabla_w = self.backprop(x, y) nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)] nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)] self.weights = [(1-eta*(lmbda/n))*w-(eta/len(mini_batch))*nw for w, nw in zip(self.weights, nabla_w)] self.biases = [b-(eta/len(mini_batch))*nb for b, nb in zip(self.biases, nabla_b)] def backprop(self, x, y): """Return a tuple ``(nabla_b, nabla_w)`` representing the gradient for the cost function C_x. ``nabla_b`` and ``nabla_w`` are layer-by-layer lists of numpy arrays, similar to ``self.biases`` and ``self.weights``.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] # feedforward activation = x activations = [x] # list to store all the activations, layer by layer zs = [] # list to store all the z vectors, layer by layer for b, w in zip(self.biases, self.weights): z = np.dot(w, activation)+b zs.append(z) activation = sigmoid(z) activations.append(activation) # backward pass delta = (self.cost).delta(zs[-1], activations[-1], y) nabla_b[-1] = delta nabla_w[-1] = np.dot(delta, activations[-2].transpose()) # Note that the variable l in the loop below is used a little # differently to the notation in Chapter 2 of the book. Here, # l = 1 means the last layer of neurons, l = 2 is the # second-last layer, and so on. It's a renumbering of the # scheme in the book, used here to take advantage of the fact # that Python can use negative indices in lists. for l in xrange(2, self.num_layers): z = zs[-l] sp = sigmoid_prime(z) delta = np.dot(self.weights[-l+1].transpose(), delta) * sp nabla_b[-l] = delta nabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) return (nabla_b, nabla_w) def accuracy(self, data, convert=False): """Return the number of inputs in ``data`` for which the neural network outputs the correct result. The neural network's output is assumed to be the index of whichever neuron in the final layer has the highest activation. The flag ``convert`` should be set to False if the data set is validation or test data (the usual case), and to True if the data set is the training data. The need for this flag arises due to differences in the way the results ``y`` are represented in the different data sets. In particular, it flags whether we need to convert between the different representations. It may seem strange to use different representations for the different data sets. Why not use the same representation for all three data sets? It's done for efficiency reasons -- the program usually evaluates the cost on the training data and the accuracy on other data sets. These are different types of computations, and using different representations speeds things up. More details on the representations can be found in mnist_loader.load_data_wrapper. """ if convert: results = [(np.argmax(self.feedforward(x)), np.argmax(y)) for (x, y) in data] else: results = [(np.argmax(self.feedforward(x)), y) for (x, y) in data] return sum(int(x == y) for (x, y) in results) def total_cost(self, data, lmbda, convert=False): """Return the total cost for the data set ``data``. The flag ``convert`` should be set to False if the data set is the training data (the usual case), and to True if the data set is the validation or test data. See comments on the similar (but reversed) convention for the ``accuracy`` method, above. """ cost = 0.0 for x, y in data: a = self.feedforward(x) if convert: y = vectorized_result(y) cost += self.cost.fn(a, y)/len(data) cost += 0.5*(lmbda/len(data))*sum( np.linalg.norm(w)**2 for w in self.weights) return cost def save(self, filename): """Save the neural network to the file ``filename``.""" data = {"sizes": self.sizes, "weights": [w.tolist() for w in self.weights], "biases": [b.tolist() for b in self.biases], "cost": str(self.cost.__name__)} f = open(filename, "w") json.dump(data, f) f.close() #### Loading a Network def load(filename): """Load a neural network from the file ``filename``. Returns an instance of Network. """ f = open(filename, "r") data = json.load(f) f.close() cost = getattr(sys.modules[__name__], data["cost"]) net = Network(data["sizes"], cost=cost) net.weights = [np.array(w) for w in data["weights"]] net.biases = [np.array(b) for b in data["biases"]] return net #### Miscellaneous functions def vectorized_result(j): """Return a 10-dimensional unit vector with a 1.0 in the j'th position and zeroes elsewhere. This is used to convert a digit (0...9) into a corresponding desired output from the neural network. """ e = np.zeros((10, 1)) e[j] = 1.0 return e def sigmoid(z): """The sigmoid function.""" return 1.0/(1.0+np.exp(-z)) def sigmoid_prime(z): """Derivative of the sigmoid function.""" return sigmoid(z)*(1-sigmoid(z))
코드에서 더 흥미로운 변경 사항 중 하나는 L2 정규화를 포함했다는 것입니다. 이는 중요한 개념적 변화지만 구현하기가 매우 간단하여 코드에서 놓치기 쉽습니다. 대부분의 경우 lmbda 파라미터를 다양한 메서드, 특히 Network.SGD 메서드에 전달하는 것과 관련됩니다. 실제 작업은 프로그램의 단 한 줄, Network.update_mini_batch 메서드의 마지막에서 네 번째 줄에서 수행됩니다. 바로 그것에서 가중치 감쇠를 포함하여 경사 하강법 업데이트 규칙을 수정합니다. 이 수정은 사소한 것처럼 보이지만 결과에 큰 영향을 미칩니다.
참고로, 이는 신경망에서 새로운 기술을 구현할 때 흔히 발생하는 일입니다. 우리는 정규화에 대해 수천 단어를 쏟아 부었습니다. 개념적으로 매우 미묘하고 이해하기 어렵습니다. 그러나 프로그램에 추가하는 것은 매우 간단했습니다. 정교한 기술이 코드에 작은 수정많으로 구현될 수 있다는 것은 놀라울 정도로 자주 발생합니다.
코드의 또 다른 사소하게 보이지만 중요한 변경사항은 확률적 경사 하강법 메서드인 Network.SGD에 여러 선택적 플래그를 추가한 것입니다. 이러한 플래그를 사용하면 training_data 또는 Network.SGD에 전달할 수 있는 evaluation_data 세트에서 비용 및 정확도를 모니터링할 수 있습니다. 이 장의 앞부분에서 이러한 플래그를 자주 사용했지만, 작동 방식을 상기시켜 드리기 위해 간단한 예를 들어보겠습니다.
>>> import mnist_loader >>> training_data, validation_data, test_data = \ ... mnist_loader.load_data_wrapper() >>> import network2 >>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost) >>> net.SGD(training_data, 30, 10, 0.5, ... lmbda = 5.0, ... evaluation_data=validation_data, ... monitor_evaluation_accuracy=True, ... monitor_evaluation_cost=True, ... monitor_training_accuracy=True, ... monitor_training_cost=True)
여기서 우리는 evaluation_data를 validation_data로 설정하고 있습니다. 하지만 test_data나 다른 데이터 세트에서도 성능을 모니터링할 수 있습니다. 또한 evaluation_data와 training_data 모두에서 비용과 정확도를 모니터링하도록 지시하는 네 개의 플래그가 있습니다. 이러한 플래그는 기본적으로 False이지만 여기서 우리 Network의 성능을 모니터링하기 위해 활성화되었습니다. 또한 network2.py의 Network.SGD 매서드는 모니터링 결과를 나타내는 네 개의 요소로 이루어진 튜플을 반환합니다. 다음과 같이 사용할 수 있습니다.
>>> evaluation_cost, evaluation_accuracy, ... training_cost, training_accuracy = net.SGD(training_data, 30, 10, 0.5, ... lmbda = 5.0, ... evaluation_data=validation_data, ... monitor_evaluation_accuracy=True, ... monitor_evaluation_cost=True, ... monitor_training_accuracy=True, ... monitor_training_cost=True)
예를 들어 evaluation_cost는 각 에포크가 끝날 때 평가 데이터에 대한 비용을 담고 있는 30개의 요소로 이루어진 리스트가 됩니다. 이러한 정류의 정보는 신경망의 동작을 이해하는데 매우 유용합니다. 예를 들어, 시간이 지남에 따라 신경망이 어떻게 학습하는지 보여주는 그래프를 그리는데 사용할 수 있습니다. 실제로 이것이 앞 장의 부분에서 모든 그래프를 그린 방법입니다. 그러나 모니터링 플래그 중 어느 하나라도 설정되지 않으면 튜필의 해당 요소는 빈 리스트가 됩니다.
코드에 추가된 다른 기능으로는 Network 객체를 디스크에 저장하는 Network.save 메셔드와 나중에 다시 로드하는 함수가 있습니다. 저장은 파이선의 일반적인 객체 저장 및 로드 방식인 pickle이나 cPickle 모듈이 아닌 JSON을 사용하여 수행된다는 점에 유의하십시오. JSON을 사용하면 pickle이나 cPickle을 사용하는 것보다 더 많은 코드가 필요합니다. JSON을 사용한 이유를 이해하려면 미래에 Network 클래스를 시그모이드 뉴런이 아닌 다른 뉴런도 허용하도록 변경하기로 했다고 상상해 보십시오. 이러한 변경 사항을 구현하려면 Network.__init__ 매서드에 정의된 속성을 변경할 가능성이 큽니다. 단순히 객체를 피클로 저장했다면 load 함수가 실패할 것입니다. JSON을 사용하여 명시적으로 직렬화를 수행하면 이전의 Network도 여전히 로드될 수 있도록 수비게 보장할 수 있습니다.
Network2.py 코드에 다른 많은 사소한 변경사항들이 있지만, 모두 Network.py의 간단한 변경입니다. 그 결과 우리 74줄짜리 프로그램은 이제 152줄이 되었습니다.
신경망의 하이퍼파라미터를 어떻게 선택해야 할까요?
지금까지 학습률 $\eta$, 정규화 파라미터 $\lambda$ 등과 같은 하이퍼파라미터의 값들을 어떻게 선택했는지 설명하지 않았습니다. 그저 꽤 잘 작동하는 값으로 설정했을 뿐입니다. 실제로 신경망을 사용하여 문제를 해결할 때 적절한 하이퍼파라미터를 찾는 것은 어려울 수 있습니다. 예를 들어, MNIST 문제를 처음 접했고 어떤 하이퍼파라미터를 사용해야 할지 전혀 모르는 상태에서 작업을 했다고 상상해봅시다. 즉, 30개의 은닉 뉴런, 미니 배치 크기 10, 교차 엔트로피를 사용하여 30번의 에포크 동안 학습시키는 것입니다. 하지만, $\eta = 10.0$과 정규화 파라미터 $\lambda = 1000.0$을 선택합니다. 이렇게 한번 실행해보면 다음과 같은 결과를 얻을 수 있습니다.
>>> import mnist_loader >>> training_data, validation_data, test_data = \ ... mnist_loader.load_data_wrapper() >>> import network2 >>> net = network2.Network([784, 30, 10]) >>> net.SGD(training_data, 30, 10, 10.0, lmbda = 1000.0, ... evaluation_data=validation_data, monitor_evaluation_accuracy=True) Epoch 0 training complete Accuracy on evaluation data: 1030 / 10000 Epoch 1 training complete Accuracy on evaluation data: 990 / 10000 Epoch 2 training complete Accuracy on evaluation data: 1009 / 10000 ... Epoch 27 training complete Accuracy on evaluation data: 1009 / 10000 Epoch 28 training complete Accuracy on evaluation data: 983 / 10000 Epoch 29 training complete Accuracy on evaluation data: 967 / 10000
이렇게 실행하면 분류 정확도는 무작위 추측보다 나을게 없습니다. 우리 신경망은 무작위 노이즈 생성기 처럼 작동합니다.
그냥 학습률과 정규화 파라미터를 줄여서 쉽게 고칠 수 있다고 생각할 수도 있습니다. 불행히도 어떤 하이퍼파라미터를 조정해야 하는지 미리 알 수는 없습니다. 어쩌면 진짜 문제는 다른 하이퍼파라미터를 어떻게 선택하던 30개의 은닉 뉴런을 가진 우리 신경망이 제대로 작동하지 않을 수도 있다는 것입니다. 어쩌면 최소 100개의 은닉 뉴런이 필요할 수도 있습니다. 아니면 300개의 은닉 뉴런, 아니면 여러 개의 은닉 층이 필요할 수도 있습니다. 또, 출력을 인코딩하는 다른 방법이 필요할 수도 있습니다. 어쩌면 더 많은 에포크 동안 학습시켜야할 수도 있습니다. 미니 배치가 너무 작을 수도 있습니다. 이차 비용함수로 다시 전환하는 것이 더 나을 수도 있습니다. 가중치 초기화에 다른 접근 방식을 시도해야할 수도 있습니다. 이와 같은 것들이 끝없이 계속될 수 있습니다. 하이퍼파라미터 공간에서 길을 잃기 쉽습니다. 신경망이 매우 크거나 많은 양의 학습 데이터를 사용하는 경우 특히 답답할 수 있습니다. 몇 시간, 며칠 심지어 몇 주동안 학습을 시켜도 아무런 결과를 얻지 못할 수 있기 때문입니다. 상황이 계속되면 자신감이 떨어집니다. 어쩌면 신경망이 당신의 문제에 대한 잘못된 접근 방식이라는 생각이 들지도 모릅니다.
이 섹션에서는 신경망에서 하이퍼파라미터를 설정하는 데 사용할 수 있는 몇가지 경험적 방법을 설명합니다. 목표는 하이퍼파라미터 설정 작업을 꽤 잘 수행할 수 있도록 워크플로를 개발하는 데 도움을 주는 것입니다. 물론 하이퍼파라미터 최적화에 대한 모든 것을 다루지는 않을 것입니다. 이는 방대한 주제이며 어떤 경우에도 완벽하게 해결할 수 있는 문제가 아니며 어떤 전략을 사용해야 하는지에 대해 실무자들 사이에서 보편적인 합의가 있는 것도 아닙니다. 신경망에서 약간의 성능 향상을 위해 시도해 볼 수 있는 방법은 항상 하나 더 있습니다. 하지만 이 섹션의 다루는 경험적인 방법들이 도움이 될 것입니다.
광범위한 전략: 신경망을 사용하여 새로운 문제를 해결할 때 첫 번재 과제는 사소하지 않은 학습, 즉 신경망이 무작위 추측보다 더 나은 결과를 얻도록 하는 것입니다. 특히 새로운 종류의 문제에 직면했을 때 이는 놀라울 정도로 어려울 수 있습니다. 이러한 어려움을 겪고 있다면 사용할 수 있는 몇가지 전략을 살펴보겠습니다.
예를 들어 MNIST를 처음으로 다룬다고 가정해 보겠습니다. 처음에는 의욕이 넘치겠지만 위의 예시처럼 첫 번째 신경망이 완전히 실패했을 때 약간 실망할 수 있습니다. 해결 방법은 문제를 단순화하는 것입니다. 0 또는 1 이미지 외의 모든 학습 및 검증 이미지를 제거하십시오. 그런 다음 0과 1을 구별하도록 신경망을 학습시켜 보십시오. 열 자릿수를 모두 구별하는 것보다 본질적으로 쉬운 문제일 뿐만 아니라 학습 데이터양을 80% 줄여 학습 속도를 5배 높입니다. 이를 통해 훨씬 더 빠른 실험이 가능해지고, 따라서 좋은 신경망을 구축하는 방법에 대한 통찰력을 더 빠르게 얻을 수 있습니다.
의미 있는 학습을 할 가능성이 가장 높은 가장 간단한 신경망으로 네트워크를 줄여 실험 속도를 더욱 높일 수 있습니다. [784, 10] 크기의 신경망이 MNIST 숫자를 무작위로 추측하는 것보다 더 잘 분류할 수 있다고 생각되면 이러한 신경망으로 실험을 시작하십시오. [784, 30, 10] 신경망을 학습시키는 것보다 훨씬 빠르며 나중에 후자로 확장할 수도 있습니다.
모니터링 빈도를 높여 실험 속도를 더욱 높일 수 있습니다. network2.py에서는 각 훈련 에포크가 끝날 때, 성능을 모니터링 합니다. 에포크당 50,000개의 이미지가 있으므로 [784, 30, 10] 신경망을 학습시킬 때, 내 노트북에서 에포크 당 약 10초 정도 기다려야 신경망이 얼마나 잘 학습하고 있는지에 대한 피드백을 얻을 수 있습니다. 물론 약 10초 정도의 시간은 그리 길지 않지만 수십 가지 하이퍼파라미터 선택을 시험해보고 싶다면 성가시고, 수백 또는 수천 가지 선택을 시험해 보고 싶다면 점점 더 힘들게 됩니다. 예를 들어 1,000개 학습 이미지가 끝날 때마다 검증 정확도를 더 자주 모니터링하여 피드백을 더 빠르게 얻을 수 있습니다. 또한 전체 10,000개 이미지 검증 세트를 사용하여 성능을 모니터링하는 대신 100개의 검증 이미지만 사용하여 훨씬 더 빠른 추정치를 얻을 수 있습니다. 신경망이 실제 학습을 하고 상당히 정확한 대략적인 성능 추정치를 얻을 수 있을 만큼 충분한 이미지를 보는 것이 중요합니다. 물론 우리 프로그램 network2.py는 현재 이러한 종류의 모니터링을 수행하지 않습니다. 그러나 설명을 위해 유사한 효과를 얻기 위한 임시방편으로 학습 데이터를 처음 1,000개의 MNIST 학습 데이터로 줄이겠습니다. 한번 시도해보고 어떤 결과가 나오는지 살펴보기로 하겠습니다. (아래 코드를 간단하게 유지하기 위해 0과 1 이미지만 사용하는 아이디어를 구현하지는 않겠습니다. 물론 약간의 추가 작업으로 가능합니다.)
>>> net = network2.Network([784, 10]) >>> net.SGD(training_data[:1000], 30, 10, 10.0, lmbda = 1000.0, \ ... evaluation_data=validation_data[:100], \ ... monitor_evaluation_accuracy=True) Epoch 0 training complete Accuracy on evaluation data: 10 / 100 Epoch 1 training complete Accuracy on evaluation data: 10 / 100 Epoch 2 training complete Accuracy on evaluation data: 10 / 100
아직도 완전한 노이즈만 나오고 있습니다. 하지만 큰 성과가 있습니다. 이제 약 10초마다 한 번씩 피드백을 받는 대신 1초도 안되는 짧은 시간 안에 피드백을 받을 수 있게 되었습니다. 이는 다른 하이퍼파라미터 선택을 더 빠르게 실험하거나 심지어 많은 다양한 하이퍼파라미터 선택을 거의 동시에 시험하는 시험을 수행할 수 있다는 것을 의미합니다.
위의 예에서 이전과 마찬가지로 $\lambda$를 $\lambda = 1000.0$으로 그대로 두었습니다. 그러나 학습 예제의 수를 변경했으므로 가중치 감쇠를 동일하게 유지하려면 실제로 $\lambda$를 변경해야 합니다. 즉, $\lambda$를 20/0으로 변경해야 합니다. 그렇게 하면 다음과 같은 결과가 나타납니다.
>>> net = network2.Network([784, 10]) >>> net.SGD(training_data[:1000], 30, 10, 10.0, lmbda = 20.0, \ ... evaluation_data=validation_data[:100], \ ... monitor_evaluation_accuracy=True) Epoch 0 training complete Accuracy on evaluation data: 12 / 100 Epoch 1 training complete Accuracy on evaluation data: 14 / 100 Epoch 2 training complete Accuracy on evaluation data: 25 / 100 Epoch 3 training complete Accuracy on evaluation data: 18 / 100
아하! 개선의 징후가 보였습니다. 아주 좋은 징후는 아니지만, 어쨌든 징후는 잡혔습니다. 이것을 바탕으로 하이퍼파라미터를 수정하여 더 나은 개선을 시도할 수 있습니다. 아마도 학습률을 더 높여할 것으로 추측할 수 있습니다. (곧 이를 논의하게되겠지만, 이는 그리 좋은 선택은 아닙니다.) 그래서 우리의 추측을 시험하기 위해 $\eta$를 100.0으로 올려보겠습니다.
>>> net = network2.Network([784, 10]) >>> net.SGD(training_data[:1000], 30, 10, 100.0, lmbda = 20.0, \ ... evaluation_data=validation_data[:100], \ ... monitor_evaluation_accuracy=True) Epoch 0 training complete Accuracy on evaluation data: 10 / 100 Epoch 1 training complete Accuracy on evaluation data: 10 / 100 Epoch 2 training complete Accuracy on evaluation data: 10 / 100 Epoch 3 training complete Accuracy on evaluation data: 10 / 100
별로 좋지 않군요. 이는 우리의 추측이 틀렸고, 문제가 학습률이 너무 낮았던 것이 아니라는 것을 시사합니다. 그래서 대신 $\eta$를 $\eta = 1.0$으로 낮추어 보겠습니다.
>>> net = network2.Network([784, 10]) >>> net.SGD(training_data[:1000], 30, 10, 1.0, lmbda = 20.0, \ ... evaluation_data=validation_data[:100], \ ... monitor_evaluation_accuracy=True) Epoch 0 training complete Accuracy on evaluation data: 62 / 100 Epoch 1 training complete Accuracy on evaluation data: 42 / 100 Epoch 2 training complete Accuracy on evaluation data: 43 / 100 Epoch 3 training complete Accuracy on evaluation data: 61 / 100
훨씬 낫군요. 그리고 우리는 계속해서 각 하이퍼파라미터를 개별적으로 조정하여 점진적으로 성능을 향상시킬 수 있습니다. $\eta$에 대한 개선된 값을 찾기 위해 탐색한 후에는 $\lambda$에 대한 좋은 값을 찾는 것으로 넘어갑니다. 그런 다음 10개의 은닉 뉴런이 있는 네트워크와 같이 더 복잡한 아키텍처를 실험해봅니다. 그런 다음 $\eta$와 $\lambda$의 값을 다시 조정합니다. 그런 다음 20개의 은닉 뉴런으로 늘립니다. 그리고 다른 하이퍼파라미터를 더 조정합니다. 그러고 다른 하이퍼파라미터를 더 조정합니다. 이러한 과정을 거치면서 각 단계에서 보류된 검증 데이터를 사용하여 성능을 평가하고 이러한 평가를 사용하여 점점 더 나은 하이퍼파라미터를 찾습니다. 그렇게 함에 따라 일반적으로 하아퍼파라미터 수정으로 인한 영향을 확인하는 데 시간이 더 오래 걸리므로 모니터링 빈도를 점차적으로 줄일 수 있습니다.
이 모든 것이 광범위한 전략으로 매우 유망해 보입니다. 그러나 신경망이 전혀 학습할 수 있도록 하는 하이퍼파라미터를 찾는 초기 단계로 돌아가고 싶습니다. 사실 위의 논의조차 너무 긍정적인 전망을 전달하고 있습니다. 아무것도 학습하지 않는 신경망으로 작업하는 것은 엄청나게 좌절스러울 수 있습니다. 며칠 동안 하이퍼파라미터를 조정해도 의미 있는 응답을 얻지 못할 수 있습니다. 따라서 초기 단계에서는 실험에서 빠른 피드백을 얻을 수 있도록 해야 한다는 점을 다시 강조하고 싶습니다. 직관적으로 문제를 단순화하고 아키텍처를 단순화하는 것이 단순히 숙도를 늦출 것처럼 보일 수 있습니다. 사실 이는 의미 있는 진후를 가진 신경망을 훨씬 더 빠르게 찾을 수 있기 때문에 속도를 높입니다. 그러한 징후를 얻고 나면 하이퍼파라미터를 조정하여 종종 빠른 개선을 얻을 수 있습니다. 인생의 많은 일과 마찬가지로 시작하는 것이 가장 어려울 수 있습니다.
좋습니다. 이것이 광범위한 전략입니다. 이제 하이퍼파라미터 설정을 위한 몇 가지 구체적인 권장 사항을 살펴보겠습니다. 학습률 $\eta$, L2 정규화 파라미터 $\lambda$, 미니 배치 크기에 중점을 둘 것입니다. 그러나 많은 언급은 신경망 아키텍처, 다른 형태의 정규화, 그리고 두시부분에 나올 운동량 계수와 같은 다른 하이퍼파라미터에도 적용됩니다.
학습률: 세 가지 다른 학숩률, 각각 $\eat = 0.025, \eta = 0.25, \eta = 2.5$를 사용하여 세 개의 MNIST 신경망을 학습시킨다고 가정해 보겠습니다. 이전 섹션의 실험과 동일하게 다른 하이퍼파라미터들을 설정하고, 미니 배치 크기는 10으로, $\lambda = 5.0$으로 30 에포크 동안 실행합니다. 또한 전체 50,000개의 학습 이미지를 다시 사용합니다. 다음은 학습 진행에 따른 학습 비용 변화를 보여주는 그래프입니다.
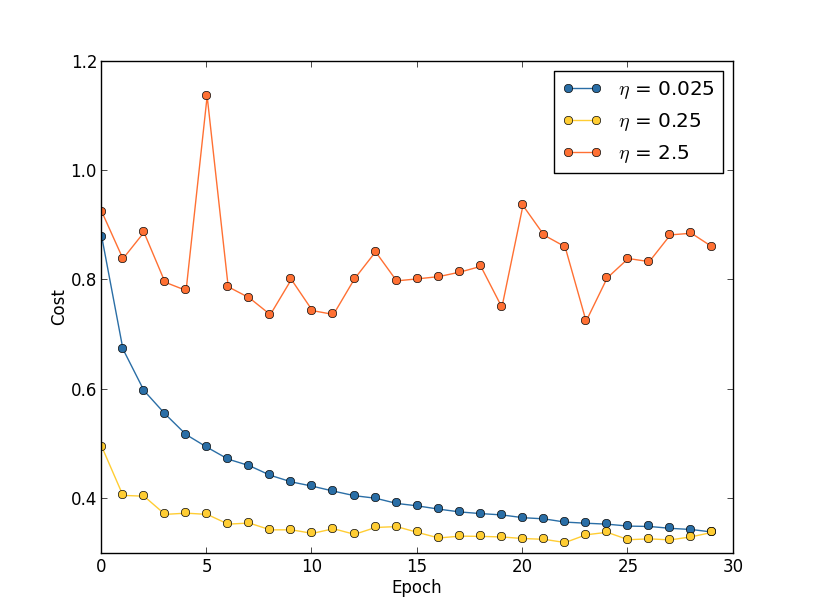
$\eta = 0.025$일 때 비용은 최종 에프크까지 부드럽게 감소합니다. $\eta = 0.25$일 때 비용은 처음에는 감소하지만 약 20 에포크 후에는 포화 상태에 가까워지고 그 이후의 대부분의 변화는 단지 작고 명백히 무작위적인 진동일 뿐입니다. 마지막으로 $\eta = 2.5$일 때 비용은 처음부터 큰 진동을 보입니다. 이러한 진동의 이유를 이해하려면 확률적 경사 하강법이 비용 함수의 계곡으로 점진적으로 내려가도록하는 것이라고 상기하십시오.

그러나 $\eta$가 너무 크면 단계가 너무 커서 실제로 최솟값을 지나칠 수 있으며, 이는 알고리즘이 계곡에서 벗어나도록 만듭니다. 그것이 $\eta = 2.5$일 때 비용이 진동하는 주된 원인일 것입니다. $\eta = 0.25$를 선택하면 초기 단계에서는 비용 함수의 최소값을 향해 이동하지만, 그 최소값에 가까워지면 과도하게 이동하는 문제가 발생하기 시작합니다. 그리고 $\eta = 0.025$를 선택하면 처음 30에포크 동안에는 이러한 문제가 전혀 발생하지 않습니다. 물론 $\eta$를 너무 작게 선택하면 확률적 경사 하강법의 속도가 느려지는 또 다른 문제가 발생합니다. 더 나은 접근 방식은 $\eta = 0.25$로 시작하여 20 에포크 동안 학습 한다음 $\eta = 0.025$로 전환하는 것입니다. 이러한 가변 학습률 스케줄에 대해서는 나중에 논의할 것입니다. 그러나 지금은 학습률 $\eta$에 대한 단일한 좋은 값을 찾는 방법에 집중하도록 하겠습니다.
이러한 그림을 염두해 두고 다음과 같이 $\eta$를 설정할 수 있습니다. 먼저 학습 데이터에 대한 비용이 진동하거나 증가하는 대신 즉시 감소하기 시작하는 $\eta$의 임계값을 추정합니다. 이 추정치는 너무 정확할 필요는 없습니다. $\eta = 0.01$부터 시작하여 대략적인 크기를 추정할 수 있습니다. 처음 몇 에포크 동안 비용이 감소하면 $\eta = 0.1, 1.0, ...$을 차례로 시도하여 처음 몇 에포크 동안 비용이 진동하거나 증가하는 $\eta$ 값을 찾을 때까지 계속합니다. 이 절차를 따르면 $\eta$의 임계값에 대한 대략적인 크기를 얻을 수 있습니다. ㅓㄴ택적으로 추정치를 개선하여 처음 몇 에포크 동안 비용이 감소하는 가장 큰 $\eta$ 값 (예: $\eta = 0.5 또는 $\eta = 0.2$)를 선택할 수 있습니다. (이것은 매우 정확할 필요는 없습니다.) 이것은 $\eta$의 임계값에 대한 추정치를 제공합니다.
분명히 사용하는 $\eta$의 실제 값은 임계값보다 크면 안됩니다. 사실 $\eta$ 값이 여러 에포크 동안 사용 가능하려면 임계값보다 작은 값(예: 임계값의 절반)을 사용하는 것이 좋습니다. 이러한 선택은 일반적으로 학습 속도를 너무 많이 늦추지 않고도 여러 에포크 동안 학습할 수 있도록 해줍니다.
MNIST 데이터의 경우 이 전략을 따르면 $\eta$ 임계값의 대략적인 크기로 0.1을 얻습니다. 추가적인 개선을 통해 임계값 $\eta = 0.5$를 얻습니다. 위의 처방에 따라 학습률로 $\eta = 0.25$를 사용하는 것이 좋습니다. 실제로 $\eta = 0.5$를 사용하는 것이 30 에포크 동안 충분히 잘 작동했기 때문에 대부분 $\eta$의 더 낮은 값을 사용하는 것에 대해 걱정하지 않았습니다.
이 모든 것이 매우 간단해 보입니다. 그러나 학습 비용을 사용하여 $\eta$를 선택하는 것은 이 섹션의 앞부분에서 검증 데이터를 사용하여 성능을 평가하여 하이퍼파라미터를 선택하는 것이라고 말한 내용과 모순되는 것처럼 보입니다. 실제로 정규화 하아퍼파라미터, 미니 배치크기, 신경망 계층 수 및 은닉 뉴런 수와 같은 신경망 파라미터 등을 선택하는 데 검증 정확도를 사용할 것입니다. 학습률에 대해서만 다르게 처리하는 이유는 무엇입니까? 솔직히 이 선택은 개인적인 선호이며 다소 특이하게 보일 수 있습니다. 그 이유는 다른 하아퍼파라미터는 테스트 데이터의 최종 분류 정확도를 향상시키기 위한 것이므로 검증 정확도를 기반으로 선택하는 것이 합리적이기 때문입니다. 그러나 학습률은 최종 분류 정확도에 부수적으로만 영향을 미칩니다. 주요 목적은 실제로 경사 하강법에서 단계 크기를 제어하는 것이며, 훈련 비용을 모니터링하는 것이 단계 크기가 너무 큰지 감지하는 가장 좋은 방법입니다. 그렇긴 하지만 이것은 개인적인 선호입니다. 학습 초기에 학습 비용은 일반적으로 검증 정확도가 향상될 때문 감소하므로 실제로 어떤 기준을 사용하든 큰 차이가 없을 것입니다.
학습 에포크 수를 결정하기 위한 조기 종료: 이 장 앞부분에서 논의한 것처럼, 조기 종료는 각 에포크가 끝날 때마다 검증 데이터에 대한 분류 정확도를 계산해야 한다는 것을 의미합니다. 개선이 멈추면 종료합니다. 이렇게 하면 에포크 수를 설정하는 것이 매우 간단해집니다. 특히, 에포크 수가 다른 하이퍼파라미터에 어떻게 의존하는지 명시적으로 알아낼 필요가 없다는 것을 의미합니다. 대신 이는 자동으로 처리됩니다. 또한 조기 종료는 과적합을 자동으로 방지합니다. 물론 이는 좋은 일이지만 실험 초기 단계에서는 과적합의 징후를 확인하고 이를 정규화 접근 방식에 반영하기 위해 조기 종료를 해제하는 것이 도움이 될 수 있습니다.
조기 종료를 구현하려면 분류 정확도가 개선을 멈추었다는 것이 정확히 뭉서을 의미하는지 더 정확하게 설명해야합니다. 살펴본 것처럼 정확도는 전반적인 추사게 개선되는 경우에도 상당히 많이 변돌할 수 있습니다. 정확도가 처음 감소했을 때 멈추면 더 많은 개선의 여지가 있는 경우에도 거의 확실하게 멈추게 됩니다. 더 나은 규칙은 최적의 분류 정확도가 상당 기간 동안 개선되지 않으면 종료하는 것입니다. 예를 들어 MNIST를 수행한다고 가정해 보겠습니다. 그러면 마지막 10번의 에포크 동안 분류 정확도가 개선되지 않으면 종료하도록 선택할 수 있습니다. 이렇게 하면 학습 중의 불운으로 인해 너무 일찍 멈추는 것을 방지하는 동시에 결코 오지 않을 개선을 영원히 기다리지 않게 됩니다.
이 10회 동안 개선 없음 규칙은 MNIST 초기 탐색에 적합합니다. 그러나 신경망은 특정 분류 정확도 근처에서 상닿이 오랫동안 정체될 수 있으며, 그런 다음 다시 개선되기 시작할 수 있습니다. 정말 좋은 성능을 얻으려고 한다면 10회 동안 개선이 없을 경우 종료하는 규칙은 너무 성급하게 조기 종료하는 것일 수 있습니다. 이 경우 초기 실험에는 10회 동안 개선 없을 때 종료하는 규칙을 사용하고, 신경망 학습 방식을 더 잘 이해하면서 점차 더 관대한 규칙(예: 20회 동안 혹은 50회 동안 개선 없을 경우 종료)을 채택하는 것이 좋습니다. 물론 이는 최적화해야 하는 하이퍼파라미터가 하나 더 있다는 것을 의미합니다. 그러나 실제로 이 하이퍼파라미터를 꽤 좋은 결과를 얻도록 설정하는 것은 그리 어렵지 않은 일입니다. 마찬가지로 MNIST 이ㅗ이의 문제의 경우 문제의 세부 사항에 따라 10회 동안 개선이 없을 경우 종료하는 규칙은 너무 일찍 종료시키거나 그렇지 않을 수 있습니다. 그러나 약간의 실험을 통해 조기 종료를 위한 꽤 좋은 전략을 수비게 찾을 수 있습니다.
지금까지 MNIST 실험에서 조기 종료를 사용하지 않았습니다. 그 이유는 다양한 학습 접근 방식 간에 많은 비교를 수행해 왔기 때문입니다. 이러한 비교에서 각 경우에 동일한 에포크 수를 사용하는 것이 기본이기 때문입니다. 그러나 network2.py를 수정하여 조기 종료를 구현하는 것은 충분히 가치가 있습니다.
가변 학습률 적용(Learning rate schedule): 지금까지 학습률 $\eta$를 일정하게 유지해 왔습니다. 그러나 학습률을 변경하는 것이 종종 유리합니다. 학습 과정 초반에는 가중치가 매우 잘못되어 있을 가능성이 높습니다. 따라서 가중치가 빠르게 변경되도록 학습률을 크게 설정하는 것이 가장 좋습니다. 나중에 가중치를 더 세밀하게 조정하면서 학습률을 줄일 수 있습니다.
학습률을 어떻게 설정해가야 할까요? 많은 접근 방식을 생각해 볼 수 있습니다. 한 가지 자연스러운 접근 방식은 조기 종료와 동일한 접근법을 사용하는 것입니다. 이 접근법은 검증 정확도가 악화되기 시작할 때까지 학습률을 일정하게 유지하는 것입니다. 그런 다음 학습률을 일정량(예: 2 또는 10배) 줄입니다. 예를 들어 학습률이 초기 값보다 1,024배(또는 1,000배) 낮아질 때까지 이 과정을 여러 번 반복합니다. 그런 다음 종료합니다.
가변 학습률의 적용은 성능을 향상시킬 수 있지만 학습 스케줄에 대한 선택 가능성을 열어줍니다. 이러한 선택은 골칫거리가 될 수 있습니다. 학습 스케줄을 최적화하는 데 영원히 시간을 보낼 수 있습니다. 첫 번째 실험에서는 학습률에 대한 단일한 상수 값을 사용하는 것이 좋습니다. 그것이 좋은 첫 번재 근사치를 제공할 것입니다. 나중에 신경망에서 최고의 성능을 얻고 싶다면 여기서 설명한 방식대로 학습 스케줄을 실험해 볼 가치가 있습니다.
정규화 파라미터, $\lambda$: 처음에는 정규화 없이($\lambda = 0.0$) 시작하여 위에서 설명한 대로 $\eta$ 값을 결정하는 것을 추천합니다. 해당 $\eta$ 선택을 사용하여 검증 데이터에서 좋은 $\lambda$ 값을 선택할 수 있습니다. $\lambda = 1.0$부터 시작하여 검증 데이터의 성능을 향상시키는 데 필요한 경우 10배씩 늘리거나 줄입니다. 좋은 값을 찾았으면 $\lambda$ 값을 미세 조정할 수있습니다. 이 것이 완료되면 다시 $\eta$를 다시 최적화해야 합니다.
이 책 앞부분에서 하이퍼파라미터를 선택한 방법: 이 섹션의 권장 사항을 사용하면 이 책 앞부분에서 사용했던 값과 항상 정확히 일치하지 않는 $\eta$ 및 $\lambda$ 값을 얻게 될 것입니다. 그 이유는 책에는 때때로 하이퍼파라미터를 최적화하는 것이 비실용적인 제약들이 있기 때문입니다. 예를 들어 이차 및 교차 엔트로피 비용 함수 비교, 이전 및 새로운 가중치 초기화 방법 비교, 정규화 유무에 따른 실행 등 다양한 학습 접근 방식을 비교했던 그 모든 것들을 생각해보십시오. 이러한 비교를 의미 있게 만들기 위해 일반적으로 비교되는 접근 방식에서 하아퍼파라미터를 일정하게 유지하거나 적절한 방식으로 조정하려고 노력했습니다. 물론 모든 학습 접근 방식에 대해 동일한 하이퍼파라미터가 최적인 것은 아니므로 여기서 사용한 하이퍼파라미터는 일종의 절충안입니다.
이러한 절충안의 대안으로 모든 학습 접근 방식에 대해 하이퍼파라미터를 최대한 최적화하려고 시도할 수도 있습니다. 원칙적으로는 모든 학습 접근 방식에서 최상의 결과를 볼 수 있으므로 더 나은 공정한 접근 방식이 될 것입니다. 그러나 이러한 방식으로 수십 번의 비교를 수행했으며 실제로 계산 비용이 너무 많이 들었습니다. 그렇기 때문에 하이퍼파라미터에 대해 꽤 좋은 (그러나 최적이라고 이양기하려운 어려운) 선택을 사용하는 절충안을 채택했습니다.
미니 배치 크기: 미니 배치 크기를 어떻게 설정해야할까요? 이 질문에 대답하기 위해 먼저 미니 배치의 크기가 1인 온라인 학습(online learning, 점진적 학습)을 한다고 가정해보겠습니다.
온라인 학습에 대한 분명한 걱정은 단일 학습 예제만 포함하는 미니 배치를 사용하면 기울기 추정에 상당한 오류가 발생할 것이라는 점입니다. 하지만 실제로 오류는 큰 문제가 되지 않습니다. 그 이유는 개별 기울기 추정치가 매우 정확할 필요가 없기 때문입니다. 비용 함수가 계속 감소하는 경향을 유지할 만큼 충분히 정확한 추정치만 필요합니다. 마치 북극을 향해 가려고 하지만 볼 때마다 10~20도씩 어근나는 고장난 나침반을 가지고 있는 것과 같습니다. 나침반을 자주 확인하고 평균적으로 나침반이 올바른 방향을 가르키는 한 북극 자극에 잘 도착할 것입니다.
이러한 논리에 따르면 온라인 학습을 사용해야할 것 같습니다. 사실 상황은 그 보다 더 복잡합니다. 이전 장에서 한 문제에서 루프를 통해 처리하는 대신 미니 배치에 있는 모든 예제에 대해 동시에 기울기 업데이트를 계산하기 위해 행렬 기술을 사용할 수 있다고 언급한 바 있습니다. 하드웨어의 성능이나 선형 대수 라이브러리의 세부 사항에 따라 100개의 학습 예제를 별도로 반복하여 미니 배치 기울기 추정치를 계산하는 것보다 (예를들어) 크기가 100인 미니 배치에 대한 기울기 추정치를 계산하는 것이 훨씬 빠를 수 있습니다. 예를 들어 100배 더 오래 걸리는 대신 50배 더 오래 걸릴 수 있습니다.
이제 처음에는 이것이 그다지 도움이 되지 않을 것처럼 보입니다. 크기가 100인 미니 배치에서 가중치에 대한 학습 규칙은 다음과 같습니다. (아래 식에서 합산은 미니 배치의 모든 학습 예제에 대하여 수행합니다.)
$\begin{eqnarray} w \rightarrow w' = w-\eta \frac{1}{100} \sum_x \nabla C_x,\tag{100}\end{eqnarray}$
이것은 다음과 대비됩니다.
$\begin{eqnarray} w \rightarrow w' = w-\eta \nabla C_x\tag{101}\end{eqnarray}$
미니 배치 업데이트를 수행하는데 50배 더 오래걸리더라도 훨씬 더 자주 업데이트할 것이기 때문에 온라인 학습을 하는 것이 여전히 더 나을 수 있습니다. 그러나 미니 배치 경우에는 학습률을 100배 늘려 업데이트 규칙이 다음과 같이 된다고 가정해보겠습니다.
$\begin{eqnarray} w \rightarrow w' = w-\eta \sum_x \nabla C_x.\tag{102}\end{eqnarray}$
마치 학습률이 $\eta$인 온라인 학습을 100번 개별적으로 수행하는 것과 같습니다. 하지만 온라인 학습을 한 번 수행하는 데 거릴는 시간이 50배 밖에 걸리지 않습니다. 물론 미니 배치에서 $\Delta C_x$들이 온라인 학습에서 발생하는 누적 학습(cumulative learning)과 달리 모두 동일한 가중치들로 평가되지 않기 때문에 온라인 학습의 100개 인스턴스와 완전히 동일하지는 않습니다. 하지만 큰 미니 배치를 사용하면 속도가 빨라질 가능성이 분명히 있어 보입니다.
이러한 요인들을 염두에 두고 최적의 미니 배치 크기를 선택하는 것이 좋습니다. 너무 작으면 빠른 하드웨어에 최적화된 행렬 라이브러리의 성능을 충분히 활용할 수 없습니다. 너무 크면 가중치를 충분히 자주 업데이트 하지 않게됩니다. 필요한 것은 학습 속도를 최대화하는 절충 값을 선택하는 것입니다. 다행히 속도가 최대화되는 미니 배치 크기의 선택은 다른 하이퍼파라미터(전체 아키텍처 제외)와 비교적 독립적이므로 좋은 미니 배치 크기를 찾기 위해 이들 하이퍼파라미터를 최적화할 필요가 없습니다. 따라서 다른 하이퍼파라미터에 대해 허용 가능하지만 반드시 최적은 아닌 값을 사용한 다음 위에서 설명한 대로 $\eta$를 조정하면서 여러 다른 다른 미니 배치 크기를 시험해 보는 것이 좋습니다. 검증 정확도를 시간(에포크가 아닌 실제 경과 시간)에 따라 어떻게 변하는지 그려보고 성능 향상을 가장 빠른 미니 배치의 크기를 선택하면 됩니다. 미니 배치의 크기를 선택한 후 다른 하아퍼파라미터를 최적화할 수 있습니다.
미니 배치의 최적화에 대해서는 더 자세히 다루지 않겠습니다. 실제로 우리가 구현한 코드에서도 더 빠른 미니 배치 업데이트 방식을 전혀 사용하지 않았습니다. 거의 모든 예에서 설명이나 언급 없이 단순히 미니 배치 크기를 10으로 사용했습니다. 이 때문에 미니 배치 크기를 줄이면 학습 속도를 높일 수 있습니다. 미니 배치 크기를 줄이지 않은 이유는 부분적으로는 크기가 1을 넘는 미니 배치 크기의 사용법을 보여주기 위한 것과 또 줄임으로써 얻을 수 있는 성능 향상이 미미할 것이라 예상했기 때문입니다. 그러나 다른 실제 구현들에서는 확실히 더 빠른 미니 배치 업데이트 방식을 구현한 다음 전체 속도를 최대화하기 위해 미니 배치의 크기를 최적화하려고 노력할 것입니다.
자동화 기술: 지금까지 이러한 경험적 방법을 마치 우리가 직접 하이퍼파라미터를 최적화하는 것 처럼 설명했습니다. 이렇게 직접 최적화를 수행하는 것은 신경망이 어떻게 작동하는지 감을 잡는 데 좋은 방법입니다. 하지만 놀랍지 않게 이 과정을 자동화하려는 많은 연구가 진행되었습니다. 일반적인 기술은 하이퍼파라미터 공간의 격자를 체계적으로 검색하는 그리드 검색 방법입니다. 그리드 검색의 성과와 한계(수비게 구현할 수 있는 대안에 대한 제안 포함)에 대한 리뷰는 2012년 James Bergstra와 Yoshua Bengio의 논문에서 찾을 수 있습니다. 훨씬 더 정교한 접근 방식도 많이 제안되었습니다. 여기서 그 모든 연구들을 다루지는 않겠지만, 특히 유망한 2012년 논문을 언급하고 싶습니다. 이 논문에서는 베이지안 접근 방식을 사용하여 하이퍼파라미터를 자동으로 최적화 했습니다. 해당 논문의 코드는 공개되어 있으며, 다른 연구자들도 이를 이용하여 어느정도의 성과를 얻었습니다.
요약: 지금까지 설명한 경험 법칙들을 따른다고 해서 신경망에서 가능한 최상의 결과를 얻을 수는 없을 것입니다. 하지만 아마도 좋은 시작점과 더 나은 개선을 위한 토대가 될 것입니다. 이 장에서는 각 하이퍼파라미터들을 개벌적으로 논의했습니다. 실제로는 이들 하이퍼파라미터들 간에 상관관계가 있습니다. $\eta$를 실험하면서 완벽하다고 느꼈다가 $\lambda$를 최적화하기 시작했는데, 결국 $\eta$에 대한 최적화를 망치는 것을 발견할 수도 있습니다. 실제로는 이들 하이퍼파라미터들을 반복해가며 점차 좋은 값으로 좁혀가야 할 수도 있습니다. 무엇보다 여기서 설명한 경험 법칙은 돌에 세겨진 만고불변의 규칙이 아니라 경험에 기반한 일반적인 지침이 아닌 점을 명심하시기 바랍니다. 문제가 발생하고 있다는 징후를 찾아내고 실험하려는 의지를 가져야 합니다. 특히 이는 신경망의 동작, 특히 검증 정확도를 주의 깊게 모니터링하는 것을 의미합니다.
하이퍼파라미터 선택의 어려움은 하이퍼파라미터 선택 방법에 대한 지식이 여러 연구 논문과 소프트웨어 프로그램에 널리 퍼져 있고, 종종 개별 실무자의 미릿속에만 있다는 사실로 인하여 더욱 악화됩니다. 어떻게 진행해야하는지에 대한 (때로는 모순되는) 권장 사항을 제시하는 논문이 매우 많습니다. 그러나 이러한 지식의 대부분을 종합하고 요약한 몇 가지 특히 유용한 논문이 있습니다. Yoshua Bengio는 2012년에 심층 신경망을 포함한 신경망을 훈련하기 위해 역전파와 경사 하강법을 사용하는 것에 대한 몇 가지 실질적인 권장 사항을 제시하는 논문을 발표했습니다. Bengio는 여기서 다룬 것보다 훨씬 자세히 많은 문제, 특히 보다 체계적인 하이퍼파라미터 검색 방법 등을 논의합니다. 또 다른 좋은 논문은 Yann LeCun, Leon Bottou, Genevieve Orr 및 Klaus-Robert Muller가 1998년 발표한 논문입니다. 이 두 논문은 모두 신경망에서 일반적으로 사용되는 많은 기술을 모은 매우 유용한 2012년 책에 수록되어 있습니다. 이 책은 비싸지만 많은 논문이 출판사의 허가를 받아 각 저자에 의해 온라인에 공개되어있으며 쉽게 검색하여 찾을 수 있습니다.
이러한 논문들을 읽고 특히 스스로 실험을 해보면서 깨달은 한가지 사실은 하이퍼파라미터 최적화가 결코 완전히 해결될 수 없는 문제라는 것입니다. 성능을 향상시키기 위해 시도해 볼 수 있는 또 다른 기술이 항상 존재합니다. 작가들 사이에는 책은 결코 완성되지 않고 포기될 뿐이라는 말이 있습니다. 이는 신경망 최적화에도 마찬가지입니다. 하이퍼파라미터 공간이 너무 넓어서 최적화를 결코 완전히 끝낼 수 없고 단지 후세를 위해 신경망을 포기할 뿐입니다. 따라서 우리의 목표는 최적화 작업을 잘 수행할 수 있는 동시에 필요하다면 더 세세한 최적화를 시도할 수 있는 유연성을 제공하는 워크플로를 개발하는 것이어야 합니다.
하이퍼파라미터의 설정의 어려움 때문에 일부 사람들은 신경망이 다른 기계 학습 시굴에 비해 많은 노력을 필요로 한다고 불평합니다. 다음과 같은 불평이 그 예입니다. "잘 조정된 신경망은 문제에 대해 최고의 성능을 얻을 수 있습니다. 반면에 랜덤 포레스트(또는 SVM ...)도 좋은 대안이며, 이것은 그냥 작동합니다. 그런데 완벽한 신경망을 파악할 시간이 없습니다." 물론 실용적인 관점에서 적용하기 쉬운 기술을 갖는 것은 좋습니다. 이는 문제에 대해 처음 시작할 때 특히 그렇고, 기계 학습이 문제를 해결하는 데 도움이 될지 여부가 명확하지 않을 수도 있습니다. 반면에 최적의 성능을 얻는 것이 중요하다면 더 많은 전문 지식이 필요한 접긴 방식을 시도해야 할 수도 있습니다. 기계 학습이 항상 쉽다면 좋겠지만, 당연히 그래야할 이유는 없습니다.
다른 기술들
이 장에서 논의한 각 기술들은 그 자체로도 가치가 있지만, 그 가치만이 이들을 설명한 유일한 이유는 아닙니다. 더 큰 목적은 신경망에서 발생할 수 있는 몇가지 문제와 그 문제를 극복하는 데 도움이 될 수 있는 분석 방식을 접하는 것입니다. 어떤 의미에서 우리는 신경망에 대해 생각하는 방법을 배워왔습니다. 이 장의 나머지 부분엥서는 몇 가지 다른 기술을 간략하게 소개합니다. 이는 앞선 논의만큼 깊이가 있지는 않지만, 신경망에서 사용할 수 있는 다양한 기술에 대한 감을 제공해줄 것입니다.
확률적 경사 하강법의 변형
역전파를 이용한 확률적 경사 하강법은 MNIST 숫자 분류 문제를 해결하는데 큰 도움이 되었습니다. 하지만 비용 함수를 최적화하는 다른 많은 접근 방식이 있으며, 때로는 그러한 다른 접근 방식이 미니 배치 확률적 경사 하강법보다 우수한 성능을 제공하기도 합니다. 이 섹션에서는 헤시안 기법과 모멘텀 기법이라는 두 가지 접근 방식을 간략하게 소개합니다.
헤시안 기법(Hessian technique): 논의를 시작하기 위해 잠시 신경망을 잊도록 하겠습니다. 대신 단순히 많은 변수 $w = w_1, w_2, ...$의 함수인 비용 함수 C($C = C(w)$)를 최소화하는 추상적인 문제에 집중하겠습니다. 테일러 정의에 따르면, 점 $w$ 근처에서 비용 함수는 다음과 같이 근사화될 수 있습니다.
$\begin{eqnarray} C(w+\Delta w) & = & C(w) + \sum_j \frac{\partial C}{\partial w_j} \Delta w_j \nonumber \\ & & + \frac{1}{2} \sum_{jk} \Delta w_j \frac{\partial^2 C}{\partial w_j \partial w_k} \Delta w_k + \ldots \tag{103}\end{eqnarray}$
그리고, 이 식은 다음과 같이 단순화하여 쓸 수 있습니다.
$\begin{eqnarray} C(w+\Delta w) = C(w) + \nabla C \cdot \Delta w + \frac{1}{2} \Delta w^T H \Delta w + \ldots,\tag{104}\end{eqnarray}$
여기서 $\delta C$는 일반적인 기울기 벡터이고, H는 헤시안 행렬이라고 불리는 행렬인데 그 $jk$번째 항목은 $\partial ^2 C / \partial w_j \partial w_k$입니다. 위에서 "..."으로 표시된 고차항을 버리고 C를 근사한다고 가정해 봅시다.
$\begin{eqnarray} C(w+\Delta w) \approx C(w) + \nabla C \cdot \Delta w + \frac{1}{2} \Delta w^T H \Delta w.\tag{105}\end{eqnarray}$
미적분을 이용하면, 아래 식을 이용하여 위 식의 우항을 최소화시킬 수 있습니다.
$\begin{eqnarray} \Delta w = -H^{-1} \nabla C.\tag{106}\end{eqnarray}$
식 (105)가 비용 함수에 대한 좋은 근사식이라면, 점 $w$에서 점 $w + \nabla w = w - H^{-1}$ \delta C$로 이동하면 비용 함수가 크게 감소할 것으로 예상할 수 있습니다. 이는 비용을 최소화하기 위한 다음과 같은 알고리즘을 생각해 볼 수 있도록 합니다.
- 시작점 $w$를 선택합니다.
- 헤시안 H와 $\nabla C$를 $w$에서 계산하여, $w$를 새로운 점 $w' = w - H^{-1} \nabla C$으로 업데이트 합니다.
- 헤시안 $H'$와 $\nabla 'C$를 $w'$에서 계산하여, $w'$을 새로운 점 $w'' = w' - H'^{-1} \nabla 'C$으로 업데이트 합니다.
- ...
실제로 식 (105)는 단지 근사값일 뿐이며, 더 작은 단계를 취하는 것이 좋습니다. 우리는 $\Delta w = \eta H^{-1}\nabla C$ 만큼 $w$를 반복적으로 변경함으로써 알고리즘을 수행합니다. ($\eta$는 학습률입니다.)
비용 함수를 최소화하는 이러한 접근 방식을 헤시안 기법 또는 헤시안 최적화라고 합니다. 헤시안 방법이 표준 경사 하강법보다 더 적은 단계로 최소값에 수렴한다는 것을 보여주는 이론적, 실험적 결과가 있습니다. 특히 비용 함수의 2차 변화에 대한 정보를 통합합으로써 헤시안 접근 방식은 경사 하강법에서 발생할 수 있는 많은 병리 현상을 피할 수 있습니다. 또한 헤시안을 계산하는 데 사용할 수 있는 역전파 알고리즘의 변형도 있습니다.
헤시안 최적화가 그토록 훌륭하다면 왜 우리 신경망에서 그것을 사용하지 않았을까요? 불행하게도 이러한 좋은 속성에도 불구하고 헤시안 최적화는 실제로 적용하기가 매우 어렵습니다. 문제 중 하나는 헤시안 행렬의 엄청난 크기입니다. $10^7$의 가중치와 편향을 가진 신경망이 있다고 가정해봅시다. 이 신경망에 대한 헤시안 행렬은 $10^7 \times 10^7 = 10^{14}$ 개의 항목을 포함하게 됩니다. 이는 매우 많은 항목입니다. 그리고 이는 실제로 $H^{-1} \nabla C$를 계산하는 것을 극도로 어렵게 만듭니다. 그렇다고 해서 이를 이해하는 것이 유용하지 않다는 것을 의미하지는 않습니다. 실제로 헤시안 최적화에서 영감을 얻었지만 지나치게 큰 행렬의 문제를 피하는 경사 하강법의 많은 변형이 있습니다. 그러한 기술 중 하나인 모멘텀 기반의 경사 하강법을 살펴보겠습니다.
모멘텀 기반 경사 하강법: 직관적으로 헤시안 최적화의 장점은 기울기에 대한 정보뿐만 아니라 기울기가 어떻게 변하는지에 대한 정보도 통합한다는 점입니다. 모멘텀 기반 경사 하강법은 유사한 직관에 기반하지만 2차 도함수의 큰 행렬을 사용하지 않습니다. 모멘텀 기반을 이해하기 위해 계곡 아래로 굴러가는 공을 고려했던 경사 하강법의 원래 그림을 떠올려 보십시오. 당시 우리는 경사 하강법이 그 이름에도 불구하고 계곡 바닥으로 떨어지는 공과 느슨하게 유사하다는 것을 관찰했습니다. 모멘텀 기법은 경사 하강법을 두 가지 방식으로 수정하여 물리적 그림과 더 유사하게 만듭니다. 첫째, 최적화하려는 매개변수에 대한 "속도"개념을 도입합니다. 기울기는 물리적 힘이 속도를 변화시키고 위치에 간접적으로만 영향을 미치는 것과 매우 유사하게 "위치"가 아닌 속도를 변화시키는 역할을 합니다. 둘째, 모멘텀 방법은 속도를 점진적으로 감소시키는 경향이 있는 일종의 마찰항을 도입합니다.
더 정확한 수학적 설명을 해보겠습니다. 각 $w_j$ 변수에 대한 속도 변수인 $v = v_1, v_2, ...$를 도입합니다. 그러면 경사 하강법의 업데이트 규칙 $w \rightarrow w' = w - \eta \nabla C$를 아래와 같이 바꿀 수 있습니다.
$>\begin{eqnarray} v & \rightarrow & v' = \mu v - \eta \nabla C \tag{107}\\ w & \rightarrow & w' = w+v'.\tag{108}\end{eqnarray}$
이 방정식에서 $mu$는 신경망에서 감쇠 또는 마찰의 양을 제어하는 하이퍼파라미터입니다. 이 식의 의미를 이해하려면 먼저 마찰이 없는 즉, $\mu = 1$인 경우를 고려하는 것이 도움이 됩니다. 이 경우 방정식들을 살펴보면 "힘" $\nabla C$가 이제 속도 $v$를 수정하고, 속도는 $w$의 변화율을 제어한다는 것을 알 수 있습니다. 직관적으로 기울기 항을 반복적으로 속도에 더함으로써 속도를 증가시킵니다. 이는 여러 번의 학습 과정에서 기울기가 (대략) 같은 방향을 향하면 해당 방향으로 상당한 추진력을 얻을 수 있음을 의미합니다. 예를 들어, 우리가 경사면을 곧장 내려가는 경우를 생각해 보십시오.

지금까지 하이퍼파라미터 $\mu$의 이름을 언급하지 않았습니다. 그 이유는 $mu$를 지칭하는 표준 이름이 잘못 선택되었기 때문입니다. $\mu$를 모멘텀 계수라고 부르는데, 이는 물리학의 모멘텀 개념과 전혀 다르기 때문에 혼란스러울 수 있습니다. 오히려 마찰과 훨씬 더 밀접한 관련이 있습니다. 그러나 모멘텀 계수라는 용어가 널리 사용되므로 여기에서도 이 이름을 사용하도록 하겠습니다.
모멘텀 기법의 장점 중 하나는 경사 하강법 구현을 수정하여 모멘텀을 통합하는데 큰 노력이 들지 않는다는 것입니다. 이전과 마찬가지로 역전파를 사용하여 기울기를 계산할 수 있으며 확률적으로 선택된 매니 배치를 샘플링하는 등의 아이디어를 그대로 사용할 수 있습니다. 이러한 방식으로 우리는 기울기가 어떻게 변하는지에 대한 정보를 사용하여 헤시안 기법의 일부 장점을 취할 수있습니다. 그리고 코드에 대한 약간의 수정만으로 이를 사용할 수있습니다. 실제로 모멘텀 기법은 학습 속도를 높이기 위해 일반적으로 널리 이용됩니다.
비용 함수 최소화를 위한 다른 접근 방식: 비용 함수를 최소화하기 위한 많은 다른 접근 방식들이 개발되었으며, 어떤 접근 방식이 가장 좋은지에 대한 보편적인 합의는 없습니다. 신경망을 더 깊이 연구할수록 다른 기술들을 살펴보고, 그것들이 어떻게 작동하는지, 강점과 약점은 무엇인지, 그리고 실제로 어떻게 적용할 수 있는지를 이해할 필요가 있습니다. 앞서 언급한 논문들에는 공액 기울기 하강법(conjugate gradient descent)과 BFGS 기법(메모리를 제안하는 L-BFGS도 참조)을 포함한 여러 가지 기술들을 소개하고 비교합니다. 최근 유망한 결과를 보여준 또 다른 기술은 모멘텀 기법을 개선한 Nesterov의 가속 경사 기법입니다. 그러나 많은 문제에 대해, 특히 모멘텀을 사용하는 경우 일반적인 활률적 경사 하강법이 잘 작동하므로 이후 나머지 부분에서는 확률적 경사 하강법을 계속 사용하도록 하겠습니다.
인공 뉴런의 다른 모델
지금까지 우리는 시그모이드 뉴런을 사용하여 신경망을 구축했습니다. 원칙적으로 시그모이드 뉴런으로 구축된 신경망은 어떤 함수든지 계산할 수 있습니다. 하지만 실제로는 다른 유형의 뉴런을 사용하여 구축된 신경망이 때때로 시그모이드 신경망보다 성능이 뛰어날 수 있습니다. 응용분야에 따라 이러한 대체 유형의 뉴런을 기반으로한 신경망이 더 빨리 학습허거나 학습한 결과를 테스트 데이터에 더 잘 일반화하여 적용할 수 있습니다. 일반적으로 사용되는 몇 가지 변형에 대한 감을 잡을 수 있도록 대체 유형의 뉴런에 대해서 알아보도록 하겠습니다.
가장 간단한 변형은 시그모이드 함수를 쌍곡 탄젠트 함수로 대체하는 $tanh$ ("탄치"라고 발음) 뉴런일 것입니다. 입력 $x$, 가중치 벡터 $w$, 그리고 편향 b를 갖는 $tanh$ 뉴런의 출력은 다음과 같습니다. 여기서 tanh는 물론 쌍곡탄젠트 함수입니다.
$\begin{eqnarray} \tanh(w \cdot x+b), \tag{109}\end{eqnarray}$
쌍곡 탄젠트 함수, tanh 함수는 시그모이드 뉴런과 매우 밀접한 관련이 있음을 밝혀졌습니다. 먼저 소$tanh$가 아래와 같이 정의된다는 것을 상기하시기 바랍니다.
$\begin{eqnarray} \tanh(z) \equiv \frac{e^z-e^{-z}}{e^z+e^{-z}}.\tag{110}\end{eqnarray}$
간단한 대수학을 적용하면 다음 식을 쉽게 얻을 수 있습니다.
$\begin{eqnarray} \sigma(z) = \frac{1+\tanh(z/2)}{2},\tag{111}\end{eqnarray}$
즉, $tanh$는 시그모이드 함수를 약간 변형한 것임을 쉽게 확인할 수 있습니다. 아래는 $tanh$ 함수를 시각화한 그래프입니다. 시그모이드 함수와 매우 유사하다는 것을 알수 있습니다.

$tanh$ 뉴런과 시그모이드 뉴런의 한 가지 차이점은 $tanh$ 뉴런의 출력 범위가 0에서 1이 아닌 -1 에서 1이라는 것입니다. 이는 $tanh$ 뉴런 기반 신경망을 구축하려는 경우 시그모이드 신경망에서와 약간 다르게 출력을 정규화해야 할 수도 있고 (응용 분야에 따라서는 입력을 정규화해야 할 수도 있음) 입력도 정규화해야할 수도 있음을 의미합니다.
시그모이드 뉴런과 유사하게 $tanh$ 뉴런 신경망도 원칙적으로 입력을 -1에서 1 범위로 매핑하는 모든 함수를 계산할 수 있습니다. 또한, 역전파 및 확률적 경사 하강과 같은 아이디어는 시그모이드 뉴런 신경망에 적용하는 것만큼 쉽게 $tanh$ 뉴런 신경망에 적용할 수 있습니다.
어떤 종류의 뉴런($tanh$ 또는 시그모이드)을 신경망에 사용해야 할까요? 솔직히 말해서 정해진 답은 없습니다. 하지만 $tanh$가 때때로 더 나은 성능을 보인다는 이론적인 주장과 몇 가지 경험적 증거가 있습니다. $tanh$ 뉴런에 대한 이론적 주장중 하나를 간략하게 설명하겠습니다. 시그모이드 뉴런을 사용한다고 가정하면 신경망에 대한 모든 활성화는 양수입니다. $l+1$ 번째 계층의 $j$ 번째 뉴런에 대한 입력인 가중치 $w^{l+1}_{jk}$에 대하여 고려해 보겠습니다. 역전파 규칙에 따르면, 이에 대한 기울기는 $a^l_k \delta^{l+1}_j$입니다. 활성화가 양수이므로 이 기울기의 부호는 $\delta^{l+1}_j$의 부호와 같습니다. 이것은 $\delta^{l+1}_j$이 양수이면, 모든 가중치 $w^{l+1}_{jk}$들은 경사 하강이 적용되는 동안 감소하며, $\delta^{l+1}_j$가 음수이면 모든 가중치 $w^{l+1}_{jk}$들은 증가한다는 것을 의미합니다. 다시 말해 동일한 뉴런으로 들어오는 모든 가중치는 함께 증가하거나 함께 감소해야 합니다. 이는 일부 가중치는 증가하고 다른 가중치는 감소해야 할 수도 있으므로 문제가 됩니다. 이는 일부 입력 활성화의 부호가 다른 경우에만 발생할 수 있습니다. 이는 시그모이드 함수를 양수 및 음수 활성화를 모두 허용하는 $tanh$와 같은 활성화 함수로 대체해야하는 것을 시사합니다. 실제로 $tanh$는 원점 O에 대하여 대칭이므로 $tanh(-z) = -tanh(z)$가 됩니다. 대체적으로 은닉 계층의 활성화가 양수와 음수 사이에 균등하게 균형을 이룰 것을 예상할 수도 있습니다. 이는 가중치 업데이트가 한 방향으로 이루어지는 체계적인 편향이 없도록 하는데 도움이 될 것입니다.
이 주장을 얼마나 심각하게 받아들여야 할까요? 이 주장이 시사하는 바는 있지만, $tanh$ 뉴런이 시그모이드 뉴런보다 성능이 뛰어나다는 것도 엄격한 증명이 아닌 경험적인 사실입니다. 아마도 시그모이드 뉴런의 다른 속성이 이문제를 보완할 수도 있지 않을까요? 실제로 많은 경우에 $tanh$는 경험적으로 시그모이드 뉴런보다 성능 향상이 미비하거나 전혀 없는 것으로 나타납니다. 불행히도 특정 응용분야에서 어떤 종류의 뉴런이 가장 빠르게 학습하고 최고의 일반화 성능을 제공하는지 알 수 있는 확고한 규칙은 아직 없습니다.
시그모이드 뉴런의 또 다른 변형은 ReLU(rectified Linear Unit)라고 하는 정류된 선형(rectified linear) 뉴런입니다. 입력 $x$, 가중치 벡터 $w$, 편향 $b$를 갖는 ReLU의 출력은 다음과 같습니다.
$begin{eqnarray} \max(0, w \cdot x+b).\tag{112}\end{eqnarray}$
시각적으로 정류 함수인 $max(0 , z)$는 아래와 같습니다.

분명히 이러한 뉴런은 시그모이드 및 $tanh$ 뉴런 모두와 매우 다릅니다. 그러나 시그모이드 및 $tanh$ 뉴런과 마찬가지로 ReLU는 어떤 함수든지 계산하는데 사용될 수 있으며, 역전파 및 경사 하강과 같은 기술을 사용하여 학습시킬 수 있습니다.
시그모이드 및 $tanh$ 뉴런 대신 언제 ReLU를 사용해야 할까요? 이미지 인식에 대한 일부 최근 연구에서는 신경망의 대부분에서 ReLU를 사용하는 것이 상당한 이점이 있다는 것을 발견했습니다. 하지만 $tanh$ 뉴런과 마찬가지로 ReLU가 정확히 언제, 왜 더 나은지는 아직 깊이 이해하지 못하고 있습니다. 몇 가지 문제에 대한 감을 잡을 수 있도록 시그모이드 뉴런이 포화될 때, 즉 출력이 0 또는 1에 가까울 때 학습을 멈춘다는 것을 상기해보시기 바랍니다. 이 장에서 반복적으로 살펴 보았듯이 문제는 $\sigma'$항이 기울기를 줄여 학습 속도를 늦춘다는 것입니다. $tanh$ 뉴런도 포화되면 유사한 문제를 겪습니다. 대조적으로, ReLU에 대한 가중치가 적용된 입력을 늘려도 포화되지 않으므로 학습 속도 저하가 없습니다. 반면 ReLU에 대한 가중치가 적용된 입력이 음수이면 기울기가 사라져 뉴런이 완전히 학습을 멈춥니다. 이것들은 ReLU가 시그모이드 또는 $tanh$ 뉴런보다 언제, 왜 더 나은 성능을 보이는지 이해하기 어렵게 만드는 많은 문제 중 두 가지 일뿐입니다.
우리는 여기서 여러 유형의 뉴런에 대한 불확실성에 대하여 다루었습니다. 활성화 함수를 어떻게 선택해야 하는지에 대한 확실한 이론이 아직 없다는 점을 강조했습니다. 실제로 문제는 여기서 설명한 것보다 훨씬 더 어렵습니다. 가능한 활성화 함수가 무한히 많기 때문입니다. 주어진 문제에 가장 적합한 것은 무엇일까요? 가장 빠르게 학습하는 신경망을 만들려면 어떻게 해야할까요? 가장 높은 테스트 정확도를 얻을 수 있는 것은 무엇일까요? 이런 질문에 대한 깊고 체계적인 연구가 아직 충분히 이루어지지 않았습니다. 이상적으로는 활성화 함수를 어떻게 선택하고 (아마도 즉성에서 수정할지) 자세히 알려주는 이론이 있을 것입니다. 반면에 완전한 이론이 부족하다고 해서 멈춰서는 안 됩니다. 우리는 이미 강력한 도구를 가지고 있으며, 이러한 도구를 사용하여 많은 진전을 이룰 수 있습니다. 이 책의 나머지 부분에서는 시그모이드 뉴런이 강력하고 신경망의 핵심 아이디어에 대한 구체적인 설명을 제공하므로 계속해서 시그모이드 뉴런을 주요 뉴런으로 사용하겠습니다. 하지만 이러한 동일한 아이디어가 다른 유형의 뉴런에도 적용될 수있으며, 때로는 그렇게 하는 것이 이점이 있다는 것을 염두에 두시기 바랍니다.
신경망의 이야기에 대해
질문: 수학적으로 뒷받침되기보다는 거의 전적으로 경험을 기반으로 한 기계학습 기술을 어떻게 활용하고 연구하고 있습니까? 또한 이러한 기술 중 일부가 실패하는 상황은 언제입니까?
답변: 우리의 이론적 도구가 매우 약하다는 것을 깨달아야 합니다. 때로는 특정 기술이 작동해야 하는 이유에 대한 좋은 수학적 직관을 가지고 있습니다. 때로는 특정 기술이 작동하는 이유에 대한 좋은 수학적 직관을 가지고 있습니다. 때로는 우리의 직관이 틀릴 때도 있습니다. [...] 질문은 다음과 같습니다. 이 특정 문제에 대해 우리의 방법이 얼마나 잘 작동하는가, 그리고 그것이 잘 작동하는 문제의 집합이 얼마나 큰가.
한때, 양자학 기초에 관한 학회에 참석했을 때, 저자는 매우 이상해 보이는 말버릇을 알아차렸다. 강연이 끝나면 청중의 질문은 종종 "당신의 관점에 매우 공감하지만 [...]"으로 시작했다. 양자 기초는 저자의 평소 분야가 아니었기 때문에 다른 과학 학회에서는 질문자가 연사의 관점에 대한 공감을 표시하는 것을 거의 또는 전혀 들어본 적이 없었기 때문에 이 질문 방식을 알아챘다. 당시 저자는 이러한 질문의 유행이 양자 기초에서 진정한 진전이 거의 이루어지지 않고 사람들이 단지 쳇바퀴를 돌고 있을 뿐인데 기인한 것이라고 생각했다. 나중에 저자는 그 평가가 너무 가혹했다는 것을 깨달았다. 연사들은 인간의 마음이 이제까지 직면했던 가장 어려운 문제 중 일부와 씨름하고 있었다. 물론 진전은 느렸다. 하지만 항상 논쟁의 여지가 없는 새로운 진전을 보고할 수 없더라도 사람들은 어떻게 생각하는지에 대한 업데이트를 듣는 것에는 여전히 가치가 있었다.
현재 이 책에서 "매우 공감하지만 [...]"과 비슷한 말버릇을 눈치챗을 수도 있습니다. 우리가 보고 있는 것을 설명하기 위해 종종 "경험적으로 [...]", 또는 "대략적으로 [...]"라고 말하면서 어떤 현상을 설명하는 이야기를 덧붙였습니다. 이러한 이야기는 그럴듯하지만, 여기서 제시한 경험적 증거는 종종 매우 빈약했습니다. 연구 문헌을 살펴보면 비슷한 스타일의 이야기가 신경망에 관한 많은 연구 논문에 자주 등장하며 뒷받침하는 증거는 빈약한 경우가 많습니다. 이러한 이야기에 대해서 우리는 어떠한 자세를 가져야 할까요?
과학의 많은 분야, 특히 단순한 현상을 다루는 분야에서는 상당히 일반적인 가설에 대해 매우 확실하고 신뢰할 수 있는 증거를 얻을 수 있슨비다. 그러나 신경망에는 많은 수의 매개변수와 하이퍼파라미터가 있으며 그들 사이에는 매우 복잡한 상호 작용이 있습니다. 그러한 극도로 복잡한 시스템에는 신뢰할 수 있는 일반적인 진술을 확립하는 것이 매우 어렵습니다. 일반적인 의미에서 신경망을 이해하는 것은 양자 기초와 마찬가지로 인간 지성의 한계를 시험하는 문제입니다. 대신 우리는 종종 일반적인 진술 의 몇가지 특정 사례에 대한 찬반 증거로 만족합니다. 결과적으로 ㅐ로운 증거가 나타나면 이러한 진술을 나중에 수정하거나 포기해야할 수도 있습니다.
이러한 상황을 보는 한가지 방법은 모든 경험적 이야기나 암묵적인 도전을 내포하고 있다는 것입니다. 예를 들어 앞서 인용한 드롭아웃이 작동하는 이유를 설명하는 부분을 생각해 보십시오. 그 설명은 자극적인 설명이며 그 안에 무엇이 진실이고, 무엇이 거짓인지, 무엇이 수정되고 개선되어야 하는지 파악하기 위해 연구를 수행해야할 수 있습니다. 실제로 드롭아웃과 많은 변형들을 조사하여 작동 방식과 한계를 이해하려고 노력하는 소규모 연구자 집단이 있습니다. 그리고 우리가 논의한 많은 경험적 현상들도 마찬가지 입니다. 각 경험적 현상은 단지 (잠재적인) 설명일 뿐만 아니라 더 자세히 조사하고 이해해야 할 도전 과제이기도 합니다.
물론 한 사람이 이러한 모든 경험적 설명을 깊이 있게 조사할 시간은 없습니다. 신경망 연구자 커뮤니티가 신경망이 어떻게 학습하는지에 대한 정말 강력하고 증거 기반 이론을 개발하는 데는 수십 년 또는 그 이상이 걸릴 것입니다. 그렇다고 해서 경험적 설명을 엄밀하지 못하고 증거 기반이 충분하지 않다고 거부해야할까요? 아닙니다. 사실 우리는 우리의 생각을 고취하고 안내하기 위해 그러한 경험적 발견들이 필요합니다. 이는 탐험의 위대한 시대와 같습니다. 초기 탐험가 들은 중요한 면에서 잘못된 믿음에 기초하여 탐험하고 새로운 발견을 했습니다. 나중에 지리학에 대한 지식이 채워지면서 그 오류들이 수정되었습니다. 탐험가들이 지리를 이해했던 것처럼, 그리고 우리가 오늘날 신경망을 이해하는 것처럼, 무엇인가를 잘 이해하지 못할 때는 사고의 모든 단계에서 엄격하게 정확하기보다는 대담하게 탐험하는 것이 더 중요합니다. 따라서 이러한 이야기를 신경망에 대해 생각하는 방법에 대한 유용한 지침으로 보고 그러한 이야기의 한계에 대한 건전한 인식을 유지하고 특정 추론에 대한 증거가 얼마나 강력한지 주의 깊게 추적해야합니다. 다시 말해 우리에게 동기를 부여하고 영감을 주는 좋은 이야기가 필요하며, 문제의 실제 사실을 밝히기 위한 엄격하고 심층적인 조사가 필요 합니다.

댓글 없음:
댓글 쓰기