Deep Learning을 공부하고자 하는 많은 입문자들을 위하여 내가 공부하면서 입문서로 가장 도움이 되었던 Michael Nielsen의 온라인 도서를 여기 장별로 정리하여 두고자 한다.
이 장에서 나오는 내용들은 그의 온라인 도서 6장에 대한 내용을 한국어로 얼기설기 번역한 것이다. 번역이 어색하지만, 개념을 이해하기에는 무리가 없다고 생각한다.
지난 장에서 우리는 심층 신경망이 얕은 신경망보다 훨씬 학습시키기 어렵다는 것을 알았습니다. 심층 신경망을 학습시킬 수 있다면 얕은 신경망보다 훨씬 더 강력할 것이라고 믿을 만한 충분한 이유가 있기 때문에 이는 안타까운 일입니다. 하지만 지난 장의 내용이 낙담스럽더라도 우리는 포기하지 않을 것입니다 이번 장에서는 심층 신경망을 학습시키는데 사용할 수 있는 기술을 개발하고 실제로 적용해볼 것입니다. 또한 이미지 인식, 음성 인식 및 기타 애플리케이션을 위한 심층 신경망 사용에 대한 최근 현황을 간략히 살펴보면서 더 넓은 그림을 조망해볼 것입니다. 그리고 신경망과 인공 지능의 미래에 대한 간략한 전망도 해볼 예정입니다.
이 장은 좀 긴 편입니다. 이 장에서 다루게 될 내용들에 대하여 간략하게 먼저 살펴보도록 하겠습니다. 이번 장의 하위 섹션들은 내용적 연관성이 크지 않으므로 신경망에 대한 기본적인 이해가 있다면, 관심있는 섹션으로 바로 이동해도 괜찮습니다.
이 장의 주요 부분은 가장 널리 사용되는 심층 신경망의 유형 중 하나인 심층 합성곱 신경망(deep convolutional network)에 대한 소개입니다. MNIST 학습 데이터에서 손으로 쓴 숫자 분류 문제를 해결하기 위하여 합성곱 신경망을 사용하는 방법에 대한 자세한 사례도 다루도록 하겠습니다.

합성곱 신경망에 대한 설명은 이 책의 앞 부분에서 이 문제를 다루는데 사용한 얕은 신경망부터 시작할 예정입니다. 그리고, 얕은 신경망을 반복적으로 수정해가면서 점점 더 강력한 신경망을 구축해가도록 하겠습니다. 이 장을 진행해가면서 convolution, pooling, 얕은 신경망으로 수행했던 것보다 더 많은 것을 수행하기 위하여 GPU를 사용하는 방법, 과적합을 억제하기 위하여 알고리즘을 이용하여 학습 데이터를 확장하고 드롭아웃 기술을 활용하는 방법, 그리고 신경망 앙상블(ensembles of networks)과 같은 기법들을 활용하는 것에 대해서도 다룰 것입니다. 이런 기법들을 활용하여 신경망을 거의 인간에 버금가는 수준으로 만들어 볼 예정입니다. 학습 중에 보지 못한 10,000개의 MNIST 테스트 이미지 중에서 우리의 신경망 시스템은 9,967개를 정확하게 분류할 수 있을 것입니다. 여기서 잘못 분류된 33개의 이미지를 살짝 미리 보여드리겠습니다. 아래 그림에서 오른쪽 상단에 표시된 숫자는 올바르게 분류했을 때의 답이며, 오른쪽 하단의 숫자는 우리 신경망 시스템이 분류한 결과를 표시합니다.

이러한 이미지 중 상당수는 사람이 분류하기도 어렵습니다. 예를 들어 맨 윗줄의 세 번째 이미지를 보시기 바랍니다. 이 이미지는 숫자 "8"을 쓴 것이지만, "9"로도 보입니다. 우리 신경망도 "9"라고 인식했습니다. 이러한 종류의 오류는 최소한 납득 가능하며, 어쩌면 칭찬할 만할 수도 있습니다. 이미지 인식에 대한 논의는 신경망(특히 합성곱 신경망)을 사용하여 이미지 인식을 수행하는 최근의 놀라운 발전에 대한 개요로 마무리하도록 하겠습니다.

우리는 인접한 신경망 계층이 서로 완전히 연결된 신경망을 사용하여 학습시켰습니다. 신경망 계층이 완전히 연결되었다는 것은 신경망 내의 모든 뉴런이 인접한 계층의 모든 뉴런과 연결되어 있음을 의미합니다.

특히, 입력 이미지의 각 픽셀에 대하여 해당 픽셀의 강도를 입력 계층의 해당 뉴런 값으로 대응되도록 신경망을 설계했습니다. 즉, $28 \times 28$ 픽셀을 갖는 입력 이미지의 각 픽셀이 784개의 입력 뉴런에 하나씩 대응된다는 의미입니다. 그런 다음 신경망의 가중치와 편향을 학습시켜 신경망의 출력이 입력 이미지를 "1", "2", " ... , "8" 또는 "9"로 정확하게 식별하도록 만들었습니다.

마찬가지로, 입력 픽셀은 은닉층 뉴런에 연결될 것입니다. 하지만 모든 입력 픽셀을 모든 은닉층 뉴런에 연결하지는 않을 것입니다. 대신 입력 이미지의 작고 국소적인 영역에서만 연결을 만들도록 하겠습니다.


다음, 우리는 지역 수용장을 한 픽셀(다시말 해 한 뉴런) 오른쪽으로 이동(sliding)시켜 두번째 은닉 뉴런과 연결시킵니다.

이와 같은 방법으로 첫 번째 은닉 뉴런을 구성합니다. 만약 $28 \times 28$ 크기의 입력 이미지와 $5 \times 5$ 크기의 지역 수용장이 있다면, 은닉 계층에는 $24 \times 24$개의 뉴런이 존재할 것이라는 점에 유의하시기 바랍니다. 이는 입력 이미지의 왼쪽 끝에서 시작해서 오른쪽 끝까지 지역 수용장을 23개의 뉴런만큼, 위에서 아래까지도 23개의 뉴런만큼 이동시킬 수 있기 때문입니다.

위 예에서는 3개의 특징 맵이 있습니다. 각 특징 맵은 $5 \times 5$ 크기의 공유 가중치 세트와 하나의 공유 편향으로 정의됩니다. 그 결과 네트워크는 3가지 다른 종류의 특징을 감지할 수 있으며, 각 특징은 전체 이미지에서 감지될 수 있습니다. 위 다이어그램에서 3개의 특징 맵만 표시하고 있지만, 실제로 합성곱 신경망에서는 더 많은 특징 맵이 사용되기도 합니다. 초기 합성곱 신경만 중 하나인 LeMet-5는 MNIST 숫자를 인식하기 위하여 각각 $5 \times 5$ 크기의 지역 수용장과 관련된 6개의 특징 맵을 사용했습니다. 따라서 위에 설명된 예는 실제로 LeNet-5와 매우 유사합니다. 이 장의 뒷부분에서 개발할 예에서는 20개 및 40개의 특징 맵을 가진 합성곱 계층을 사용할 것입니다. 학습된 특징 중 일부를 간단히 살펴보겠습니다.

위 20개의 이미지는 20개의 서로 다른 특징 맵(필터 또는 커널)을 표시합니다. 각 맵은 지역 수용장의 $5 \times 5$ 가중치에 해당하는 $5 \times 5$ 블록 이미지를 나타냅니다. 흰식 블록은 더 작은 (일반적으로 작은 음수) 가중치를 의미하므로 특징 맵은 해당 입력 픽셀에 덜 반응합니다. 어두운 불록은 더 큰 가중치를 의미하므로 특징 맵은 해당 입력 픽셀에 더 많이 반응합니다. 매우 간단히 말하자면, 위의 이미지는 합성곱 계층에 반응하는 특징의 유형을 보유준다고 볼 수 있습니다.

합성곱 계층에서 $24 \times 24$개의 뉴런이 출력되므로, 폴링 후에는 $12 \times 12$개의 뉴런이 된다는 점에 유의하시기 바랍니다.

최대 폴링은 신경망이 이미지 영역 내에 특정 특징이 있는지 여부를 묻는 방법으로 간주할 수 있습니다. 그런 다음 정확한 위치정보는 버립니다. 이에 대한 직관적 설명은 일단 특징이 발견되면 다른 특징과 비교했을 때 정확한 위치 보다는 대락적인 위치만 알면된다는 것입니다. 이러한 방식의 큰 장점은 폴링된 특징의 수가 훨씬 적다는 것입니다. 따라서 이후 계층에서 필요한 매개 변수 수를 줄일 수 있습니다.

>>> import network3 >>> from network3 import Network >>> from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer >>> training_data, validation_data, test_data = network3.load_data_shared() >>> mini_batch_size = 10 >>> net = Network([ FullyConnectedLayer(n_in=784, n_out=100), SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size) >>> net.SGD(training_data, 60, mini_batch_size, 0.1, validation_data, test_data)
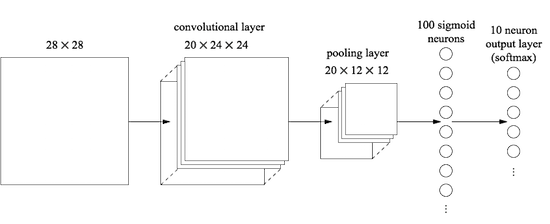
이 아키텍처에서 합성곱 및 풀링 계층은 입력되는 학습 이미지의 지역적인 공간 구조에 대하여 학습하고, 뒤쪽의 완전 연결 계층은 이미지 전체의 전역 정보를 통합하여 보다 추상적인 수준에서 학습을 하는 것으로 간주할 수 있습니다. 이러한 아키텍처는 합성곱 신경망에서 흔히 사용되고 있습니다.
>>> net = Network([ ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28), filter_shape=(20, 1, 5, 5), poolsize=(2, 2)), FullyConnectedLayer(n_in=20*12*12, n_out=100), SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size) >>> net.SGD(training_data, 60, mini_batch_size, 0.1, validation_data, test_data)
>>> net = Network([ ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28), filter_shape=(20, 1, 5, 5), poolsize=(2, 2)), ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12), filter_shape=(40, 20, 5, 5), poolsize=(2, 2)), FullyConnectedLayer(n_in=40*4*4, n_out=100), SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size) >>> net.SGD(training_data, 60, mini_batch_size, 0.1, validation_data, test_data)
>>> from network3 import ReLU >>> net = Network([ ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28), filter_shape=(20, 1, 5, 5), poolsize=(2, 2), activation_fn=ReLU), ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12), filter_shape=(40, 20, 5, 5), poolsize=(2, 2), activation_fn=ReLU), FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU), SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size) >>> net.SGD(training_data, 60, mini_batch_size, 0.03, validation_data, test_data, lmbda=0.1)
$ python expand_mnist.py
>>> expanded_training_data, _, _ = network3.load_data_shared( "../data/mnist_expanded.pkl.gz") >>> net = Network([ ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28), filter_shape=(20, 1, 5, 5), poolsize=(2, 2), activation_fn=ReLU), ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12), filter_shape=(40, 20, 5, 5), poolsize=(2, 2), activation_fn=ReLU), FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU), SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size) >>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03, validation_data, test_data, lmbda=0.1)
>>> net = Network([ ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28), filter_shape=(20, 1, 5, 5), poolsize=(2, 2), activation_fn=ReLU), ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12), filter_shape=(40, 20, 5, 5), poolsize=(2, 2), activation_fn=ReLU), FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU), FullyConnectedLayer(n_in=100, n_out=100, activation_fn=ReLU), SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size) >>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03, validation_data, test_data, lmbda=0.1)
>>> net = Network([ ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28), filter_shape=(20, 1, 5, 5), poolsize=(2, 2), activation_fn=ReLU), ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12), filter_shape=(40, 20, 5, 5), poolsize=(2, 2), activation_fn=ReLU), FullyConnectedLayer( n_in=40*4*4, n_out=1000, activation_fn=ReLU, p_dropout=0.5), FullyConnectedLayer( n_in=1000, n_out=1000, activation_fn=ReLU, p_dropout=0.5), SoftmaxLayer(n_in=1000, n_out=10, p_dropout=0.5)], mini_batch_size) >>> net.SGD(expanded_training_data, 40, mini_batch_size, 0.03, validation_data, test_data)

class FullyConnectedLayer(object): def __init__(self, n_in, n_out, activation_fn=sigmoid, p_dropout=0.0): self.n_in = n_in self.n_out = n_out self.activation_fn = activation_fn self.p_dropout = p_dropout # Initialize weights and biases self.w = theano.shared( np.asarray( np.random.normal( loc=0.0, scale=np.sqrt(1.0/n_out), size=(n_in, n_out)), dtype=theano.config.floatX), name='w', borrow=True) self.b = theano.shared( np.asarray(np.random.normal(loc=0.0, scale=1.0, size=(n_out,)), dtype=theano.config.floatX), name='b', borrow=True) self.params = [self.w, self.b] def set_inpt(self, inpt, inpt_dropout, mini_batch_size): self.inpt = inpt.reshape((mini_batch_size, self.n_in)) self.output = self.activation_fn( (1-self.p_dropout)*T.dot(self.inpt, self.w) + self.b) self.y_out = T.argmax(self.output, axis=1) self.inpt_dropout = dropout_layer( inpt_dropout.reshape((mini_batch_size, self.n_in)), self.p_dropout) self.output_dropout = self.activation_fn( T.dot(self.inpt_dropout, self.w) + self.b) def accuracy(self, y): "Return the accuracy for the mini-batch." return T.mean(T.eq(y, self.y_out))
class Network(object): def __init__(self, layers, mini_batch_size): """Takes a list of `layers`, describing the network architecture, and a value for the `mini_batch_size` to be used during training by stochastic gradient descent. """ self.layers = layers self.mini_batch_size = mini_batch_size self.params = [param for layer in self.layers for param in layer.params] self.x = T.matrix("x") self.y = T.ivector("y") init_layer = self.layers[0] init_layer.set_inpt(self.x, self.x, self.mini_batch_size) for j in xrange(1, len(self.layers)): prev_layer, layer = self.layers[j-1], self.layers[j] layer.set_inpt( prev_layer.output, prev_layer.output_dropout, self.mini_batch_size) self.output = self.layers[-1].output self.output_dropout = self.layers[-1].output_dropout
init_layer.set_inpt(self.x, self.x, self.mini_batch_size)
def SGD(self, training_data, epochs, mini_batch_size, eta, validation_data, test_data, lmbda=0.0): """Train the network using mini-batch stochastic gradient descent.""" training_x, training_y = training_data validation_x, validation_y = validation_data test_x, test_y = test_data # compute number of minibatches for training, validation and testing num_training_batches = size(training_data)/mini_batch_size num_validation_batches = size(validation_data)/mini_batch_size num_test_batches = size(test_data)/mini_batch_size # define the (regularized) cost function, symbolic gradients, and updates l2_norm_squared = sum([(layer.w**2).sum() for layer in self.layers]) cost = self.layers[-1].cost(self)+\ 0.5*lmbda*l2_norm_squared/num_training_batches grads = T.grad(cost, self.params) updates = [(param, param-eta*grad) for param, grad in zip(self.params, grads)] # define functions to train a mini-batch, and to compute the # accuracy in validation and test mini-batches. i = T.lscalar() # mini-batch index train_mb = theano.function( [i], cost, updates=updates, givens={ self.x: training_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size], self.y: training_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) validate_mb_accuracy = theano.function( [i], self.layers[-1].accuracy(self.y), givens={ self.x: validation_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size], self.y: validation_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) test_mb_accuracy = theano.function( [i], self.layers[-1].accuracy(self.y), givens={ self.x: test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size], self.y: test_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) self.test_mb_predictions = theano.function( [i], self.layers[-1].y_out, givens={ self.x: test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) # Do the actual training best_validation_accuracy = 0.0 for epoch in xrange(epochs): for minibatch_index in xrange(num_training_batches): iteration = num_training_batches*epoch+minibatch_index if iteration print("Training mini-batch number {0}".format(iteration)) cost_ij = train_mb(minibatch_index) if (iteration+1) validation_accuracy = np.mean( [validate_mb_accuracy(j) for j in xrange(num_validation_batches)]) print("Epoch {0}: validation accuracy {1:.2 epoch, validation_accuracy)) if validation_accuracy >= best_validation_accuracy: print("This is the best validation accuracy to date.") best_validation_accuracy = validation_accuracy best_iteration = iteration if test_data: test_accuracy = np.mean( [test_mb_accuracy(j) for j in xrange(num_test_batches)]) print('The corresponding test accuracy is {0:.2 test_accuracy)) print("Finished training network.") print("Best validation accuracy of {0:.2 best_validation_accuracy, best_iteration)) print("Corresponding test accuracy of {0:.2
# define the (regularized) cost function, symbolic gradients, and updates l2_norm_squared = sum([(layer.w**2).sum() for layer in self.layers]) cost = self.layers[-1].cost(self)+\ 0.5*lmbda*l2_norm_squared/num_training_batches grads = T.grad(cost, self.params) updates = [(param, param-eta*grad) for param, grad in zip(self.params, grads)]
"""network3.py ~~~~~~~~~~~~~~ A Theano-based program for training and running simple neural networks. Supports several layer types (fully connected, convolutional, max pooling, softmax), and activation functions (sigmoid, tanh, and rectified linear units, with more easily added). When run on a CPU, this program is much faster than network.py and network2.py. However, unlike network.py and network2.py it can also be run on a GPU, which makes it faster still. Because the code is based on Theano, the code is different in many ways from network.py and network2.py. However, where possible I have tried to maintain consistency with the earlier programs. In particular, the API is similar to network2.py. Note that I have focused on making the code simple, easily readable, and easily modifiable. It is not optimized, and omits many desirable features. This program incorporates ideas from the Theano documentation on convolutional neural nets (notably, http://deeplearning.net/tutorial/lenet.html ), from Misha Denil's implementation of dropout (https://github.com/mdenil/dropout ), and from Chris Olah (http://colah.github.io ). Written for Theano 0.6 and 0.7, needs some changes for more recent versions of Theano. """ #### Libraries # Standard library import cPickle import gzip # Third-party libraries import numpy as np import theano import theano.tensor as T from theano.tensor.nnet import conv from theano.tensor.nnet import softmax from theano.tensor import shared_randomstreams from theano.tensor.signal import downsample # Activation functions for neurons def linear(z): return z def ReLU(z): return T.maximum(0.0, z) from theano.tensor.nnet import sigmoid from theano.tensor import tanh #### Constants GPU = True if GPU: print "Trying to run under a GPU. If this is not desired, then modify "+\ "network3.py\nto set the GPU flag to False." try: theano.config.device = 'gpu' except: pass # it's already set theano.config.floatX = 'float32' else: print "Running with a CPU. If this is not desired, then the modify "+\ "network3.py to set\nthe GPU flag to True." #### Load the MNIST data def load_data_shared(filename="../data/mnist.pkl.gz"): f = gzip.open(filename, 'rb') training_data, validation_data, test_data = cPickle.load(f) f.close() def shared(data): """Place the data into shared variables. This allows Theano to copy the data to the GPU, if one is available. """ shared_x = theano.shared( np.asarray(data[0], dtype=theano.config.floatX), borrow=True) shared_y = theano.shared( np.asarray(data[1], dtype=theano.config.floatX), borrow=True) return shared_x, T.cast(shared_y, "int32") return [shared(training_data), shared(validation_data), shared(test_data)] #### Main class used to construct and train networks class Network(object): def __init__(self, layers, mini_batch_size): """Takes a list of `layers`, describing the network architecture, and a value for the `mini_batch_size` to be used during training by stochastic gradient descent. """ self.layers = layers self.mini_batch_size = mini_batch_size self.params = [param for layer in self.layers for param in layer.params] self.x = T.matrix("x") self.y = T.ivector("y") init_layer = self.layers[0] init_layer.set_inpt(self.x, self.x, self.mini_batch_size) for j in xrange(1, len(self.layers)): prev_layer, layer = self.layers[j-1], self.layers[j] layer.set_inpt( prev_layer.output, prev_layer.output_dropout, self.mini_batch_size) self.output = self.layers[-1].output self.output_dropout = self.layers[-1].output_dropout def SGD(self, training_data, epochs, mini_batch_size, eta, validation_data, test_data, lmbda=0.0): """Train the network using mini-batch stochastic gradient descent.""" training_x, training_y = training_data validation_x, validation_y = validation_data test_x, test_y = test_data # compute number of minibatches for training, validation and testing num_training_batches = size(training_data)/mini_batch_size num_validation_batches = size(validation_data)/mini_batch_size num_test_batches = size(test_data)/mini_batch_size # define the (regularized) cost function, symbolic gradients, and updates l2_norm_squared = sum([(layer.w**2).sum() for layer in self.layers]) cost = self.layers[-1].cost(self)+\ 0.5*lmbda*l2_norm_squared/num_training_batches grads = T.grad(cost, self.params) updates = [(param, param-eta*grad) for param, grad in zip(self.params, grads)] # define functions to train a mini-batch, and to compute the # accuracy in validation and test mini-batches. i = T.lscalar() # mini-batch index train_mb = theano.function( [i], cost, updates=updates, givens={ self.x: training_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size], self.y: training_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) validate_mb_accuracy = theano.function( [i], self.layers[-1].accuracy(self.y), givens={ self.x: validation_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size], self.y: validation_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) test_mb_accuracy = theano.function( [i], self.layers[-1].accuracy(self.y), givens={ self.x: test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size], self.y: test_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) self.test_mb_predictions = theano.function( [i], self.layers[-1].y_out, givens={ self.x: test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) # Do the actual training best_validation_accuracy = 0.0 for epoch in xrange(epochs): for minibatch_index in xrange(num_training_batches): iteration = num_training_batches*epoch+minibatch_index if iteration % 1000 == 0: print("Training mini-batch number {0}".format(iteration)) cost_ij = train_mb(minibatch_index) if (iteration+1) % num_training_batches == 0: validation_accuracy = np.mean( [validate_mb_accuracy(j) for j in xrange(num_validation_batches)]) print("Epoch {0}: validation accuracy {1:.2%}".format( epoch, validation_accuracy)) if validation_accuracy >= best_validation_accuracy: print("This is the best validation accuracy to date.") best_validation_accuracy = validation_accuracy best_iteration = iteration if test_data: test_accuracy = np.mean( [test_mb_accuracy(j) for j in xrange(num_test_batches)]) print('The corresponding test accuracy is {0:.2%}'.format( test_accuracy)) print("Finished training network.") print("Best validation accuracy of {0:.2%} obtained at iteration {1}".format( best_validation_accuracy, best_iteration)) print("Corresponding test accuracy of {0:.2%}".format(test_accuracy)) #### Define layer types class ConvPoolLayer(object): """Used to create a combination of a convolutional and a max-pooling layer. A more sophisticated implementation would separate the two, but for our purposes we'll always use them together, and it simplifies the code, so it makes sense to combine them. """ def __init__(self, filter_shape, image_shape, poolsize=(2, 2), activation_fn=sigmoid): """`filter_shape` is a tuple of length 4, whose entries are the number of filters, the number of input feature maps, the filter height, and the filter width. `image_shape` is a tuple of length 4, whose entries are the mini-batch size, the number of input feature maps, the image height, and the image width. `poolsize` is a tuple of length 2, whose entries are the y and x pooling sizes. """ self.filter_shape = filter_shape self.image_shape = image_shape self.poolsize = poolsize self.activation_fn=activation_fn # initialize weights and biases n_out = (filter_shape[0]*np.prod(filter_shape[2:])/np.prod(poolsize)) self.w = theano.shared( np.asarray( np.random.normal(loc=0, scale=np.sqrt(1.0/n_out), size=filter_shape), dtype=theano.config.floatX), borrow=True) self.b = theano.shared( np.asarray( np.random.normal(loc=0, scale=1.0, size=(filter_shape[0],)), dtype=theano.config.floatX), borrow=True) self.params = [self.w, self.b] def set_inpt(self, inpt, inpt_dropout, mini_batch_size): self.inpt = inpt.reshape(self.image_shape) conv_out = conv.conv2d( input=self.inpt, filters=self.w, filter_shape=self.filter_shape, image_shape=self.image_shape) pooled_out = downsample.max_pool_2d( input=conv_out, ds=self.poolsize, ignore_border=True) self.output = self.activation_fn( pooled_out + self.b.dimshuffle('x', 0, 'x', 'x')) self.output_dropout = self.output # no dropout in the convolutional layers class FullyConnectedLayer(object): def __init__(self, n_in, n_out, activation_fn=sigmoid, p_dropout=0.0): self.n_in = n_in self.n_out = n_out self.activation_fn = activation_fn self.p_dropout = p_dropout # Initialize weights and biases self.w = theano.shared( np.asarray( np.random.normal( loc=0.0, scale=np.sqrt(1.0/n_out), size=(n_in, n_out)), dtype=theano.config.floatX), name='w', borrow=True) self.b = theano.shared( np.asarray(np.random.normal(loc=0.0, scale=1.0, size=(n_out,)), dtype=theano.config.floatX), name='b', borrow=True) self.params = [self.w, self.b] def set_inpt(self, inpt, inpt_dropout, mini_batch_size): self.inpt = inpt.reshape((mini_batch_size, self.n_in)) self.output = self.activation_fn( (1-self.p_dropout)*T.dot(self.inpt, self.w) + self.b) self.y_out = T.argmax(self.output, axis=1) self.inpt_dropout = dropout_layer( inpt_dropout.reshape((mini_batch_size, self.n_in)), self.p_dropout) self.output_dropout = self.activation_fn( T.dot(self.inpt_dropout, self.w) + self.b) def accuracy(self, y): "Return the accuracy for the mini-batch." return T.mean(T.eq(y, self.y_out)) class SoftmaxLayer(object): def __init__(self, n_in, n_out, p_dropout=0.0): self.n_in = n_in self.n_out = n_out self.p_dropout = p_dropout # Initialize weights and biases self.w = theano.shared( np.zeros((n_in, n_out), dtype=theano.config.floatX), name='w', borrow=True) self.b = theano.shared( np.zeros((n_out,), dtype=theano.config.floatX), name='b', borrow=True) self.params = [self.w, self.b] def set_inpt(self, inpt, inpt_dropout, mini_batch_size): self.inpt = inpt.reshape((mini_batch_size, self.n_in)) self.output = softmax((1-self.p_dropout)*T.dot(self.inpt, self.w) + self.b) self.y_out = T.argmax(self.output, axis=1) self.inpt_dropout = dropout_layer( inpt_dropout.reshape((mini_batch_size, self.n_in)), self.p_dropout) self.output_dropout = softmax(T.dot(self.inpt_dropout, self.w) + self.b) def cost(self, net): "Return the log-likelihood cost." return -T.mean(T.log(self.output_dropout)[T.arange(net.y.shape[0]), net.y]) def accuracy(self, y): "Return the accuracy for the mini-batch." return T.mean(T.eq(y, self.y_out)) #### Miscellanea def size(data): "Return the size of the dataset `data`." return data[0].get_value(borrow=True).shape[0] def dropout_layer(layer, p_dropout): srng = shared_randomstreams.RandomStreams( np.random.RandomState(0).randint(999999)) mask = srng.binomial(n=1, p=1-p_dropout, size=layer.shape) return layer*T.cast(mask, theano.config.floatX)




이들은 각각 구슬깎기 대패, 갈색 뿌리썩음병 균, 데운 우유, 그리고 일반 회충 범주에 속합니다. ImageNet의 수동 공구 목록을 방문하여 구슬깎기 대패, 블록 대패, 모따기 대패 그리고 약 12가지 다른 유형의 대패를 포함한 여러 범주들을 확인해보시기 바랍니다. 여러분은 어떠실지 모르지만, 이 모든 도구 유형을 자신있게 구별하기는 쉽지 않습니다. 이것은 분명 MNIST 보다 훨씬 어려운 이미지 인식 과제입니다. LRMD의 신경망은 ImageNet 이미지를 정확하게 분류하는데 15.8%라는 존경할 만한 정확도를 얻었습니다. 이는 인상적으로 들리지 않을 수도 있지만, 이전 최고 결과인 9.3% 정확도에 비하면 훨씬 큰 진척이었습니다. 이렇나 도약은 신경망이 ImageNet과 같이 매우 어려운 이미지 인식 작업에 강력한 접근 방식을 제공할 수 있음을 시사했습니다.
... 1000개 카테고리 중 5개를 선택하여 이미지에 레이블을 지정하는 작업은 ILSVRC와 그 분류에 대해 오랫동안 연구해온 연구실의 일부 동료들에게 도차 매우 어려운 것으로 밝혀졌습니다. 처음에는 Amazon Mechanical Turk에 올릴 생각도 했습니다. 그러다가 유료 학부생을 모집할까 생각했습니다. 그러고 나서 저는 연구실의 전문 레이블러들만 참여하는 강도 높은 레이블링 파티를 조직했습니다. 그런 다음 GoogLeNet 예측을 사용하여 캍고리 수를 1000개에서 약 100개로 줄이는 수정된 인터페이스를 개발했습니다. 여전히 너무 어려워서 사람들은 계속 카테고리를 놓치고 오류율이 13~15%까지 올라갔습니다. 결국 GoogLeNet에 경쟁력 있게 가까워지려면 제가 직접 앉아서 고통스러울 정도로 긴 학습 과정과 그에 따른 신중한 주석 과정을 거치는 것이 가장 효율적이라는 것을 깨달았습니다. ... 레이블링은 분당 약 1개의 속도로 진행되었지만, 시간이 지남에 따라 감소했습니다. ... 일부 이미지는 쉽게 인식할 수 있는 반면 일부 이미지(예: 미세한 품종의 개, 새 또는 원숭이)는 몇 분 동안의 집중적인 노력이 필요한 경우도 있었습니다. 저는 개 품종 식별에 매우 능숙해졌습니다. ... 제가 작업한 이미지 샘플을 기준으로 GoogLeNet 분류 오류는 6.8%로 나타냈습니다. .. 제 자신의 최종 오류율은 5.1%로 약 1.7% 더 나았습니다.

이것은 꽤 충격적인 결과입니다. 이 논문에서 사용된 신경망은 KSH의 신경망과 동일한 코드를 기반으로 하고 있으며, 이는 현재 널리 사용되고 있는 유형의 신경망입니다. 이러한 신경망은 원칙적으로 연속적인 함수를 계산하지만, 이와 같은 결과는 실제로 거의 불연속적인 함수를 계산할 가능성이 있음을 시사합니다. 더 나쁜 것은 이러한 불연속성이 우리가 생각하는 합리적인 행동과는 거리가 먼 방식으로 나타난다는 점입니다. 이는 매우 우려스러운 일입니다. 게다가 무엇이 이러한 불연속성을 야기하는지 아직 제대로 이해하지 못하고 있습니다. 손실 함수(loss function) 때문일까요? 아니면 활성화 함수(activation function) 때문일까요? 신경망의 아키텍처 때문일까요? 아니면 다른 무엇 때문일 까요? 우리는 아직 정확히 모릅니다.
"적대적 음성(adversarial negatives)의 존재는 신경망이 높은 일반화 성능을 달성하는 능력과 모순되는 것처럼 보입니다. 실제로 신경망이 잘 일반화할 수 있다면 일반적인 예시와 구별할 수 없는 이 적대적 음성들에 의해 어떻게 혼란스러워질 수 있을까요? 이에 대한 설명은 적대적 음성의 집합은 확율이 극도로 낮아서 테스트 세트에서 전혀(또는 거의) 관찰되지 않지만, 조밀하게 분포되어 있어서(유리수와 유사함) 사실상 모든 테스트 사례들에서 발견된다는 것입니다."
그럼에도 불구하고 우리가 신경망을 너무나도 제대로 이해하지 못해서 이러한 종류의 결과가 최근에야 발견되었다는 사실은 안타깝습니다. 물론, 이 결과의 큰 장점은 후속 연구를 활발하게 촉진했다는 점입니다. 예를 들어 최근의 한 논문에서는 훈련된 신경망에 대해 인간에게는 "백색 소음(white noise)"처럼 보이는 이미지를 생성할 수 있지만, 신경망은 이를 특정 범주로 매우 높은 확신을 가지고 분류하는 것을 보여주었습니다. 이것은 우리가 신경망과 이미지 인식에서의 그 활용법을 이해하는 데 아직 갈 길이 멀다는 것을 보여주는 또 다른 증거입니다.
이러한 결과들에도 불구하고 전반적인 상황은 긍정적입니다. 우리는 ImageNet과 같은 매우 어려운 벤치마크에서 빠른 진전을 보여주고 있습니다. 또한, 스트리트 뷰에서 주소지 숫자를 인식하는 것과 같은 실제 문제에서도 빠른 진전을 경험하고 있습니다. 하지만 이러한 진전이 고무적이긴 해도, 벤치마크나 심지어 실제 응용 분야에서 개선을 보는 것만으로는 충분하지 않습니다. 우리는 적대적 이미지의 존재와 같은 근본적인 현상을 여전히 제대로 이해하지 못하고 있습니다. 이러한 근본적인 문제들이 여전히 발견되고 있는 상황(해결은 고사하고)에서 이미지 인식 문제를 거의 해결했다고 이야기하는 것은 시기상조입니다. 동시에 이러한 문제들은 추가적인 연구를 위한 흥미로운 자극제가 됩니다.
심층 신경망에 대한 다른 접근법들
이 책을 통해 우리는 MNIST 숫자 분류라는 한 가지 문제에 집중해왔습니다. 이 문제는 확률적 경사 하강법, 역전파, 합성곱 신경망, 정규화 등과 같은 강력한 아이디어들을 이해하게 해준 아주 좋은 문제였습니다. 하지만 동시에 협소한 문제이기도 합니다. 신경망 관련 논문들을 읽다보면, 우리가 아직 다루지 않은 만흥ㄴ 개념들, 예를 들어 순환 신경망(recurrent neural networks), 볼츠만 머신(Boltzmann machines), 생성 모델(generative models), 전이 학습(transfer learning), 강화 학습(reinforcement learning) 등등 ... 끝없이 계속해서 등장하는 아이디어들을 접하게 됩니다. 신경망은 정말 방대한 분야입니다. 하지만 많은 중요한 아이디어들이 우리가 이미 논의했던 개념들의 변형이며, 약간의 노력만으로 이해할 수 있습니다. 이 섹션에서는 아직 보지 못한 이 넓은 세계를 살짝 엿보도록 하겠습니다. 다만, 자세하거나 포괄적이지는 않습니다. 그렇게 하기에는 너무 많은 분량이 필요하기 때문입니다. 대신, 이 분야의 개념적인 풍부함을 접해보고 그 풍요로움 중 일부는 우리가 이미 다룬 내용과 연결될 수 있음을 보여주려는 인상적인 시도로 이해해주시기 바랍니다. 더 자세히 알고자 하는 분들을 위하여 외부 자료 링크도 제공하도록 하겠습니다. 물론 이 링크들 중 다수는 곧 새로운 자료로 대체될 수 있으니, 더 최신 문헌을 찾아보는 것이 좋을 수도 있습니다. 그럼에도 불구하고 많은 기본 아이디어들은 지속적으로 중요성을 잃지 않을 것이라고 생각합니다.
순환 신경망(Recurrent Neural Networks, RNNs)
우리가 다룬 순방향 신경망(Feedforward net)에서는 하나의 입력이 이후 모든 층의 뉴런의 활성화에 완전히 영향을 미칩니다. 이것은 매우 정적인 그림입니다. 신경망의 모든 것이 고정되어 있고, 얼어붙은 결정체와 같은 특성을 가집니다. 하지만 신경망의 구성 요소들이 동적인 방식으로 계속 변하도록 허용된다면 어떨까요? 예를 들어 은닉 뉴런의 행동이 이전 은닉층의 활성화 뿐만 아니라 이전 시간대의 활성화에 의해서도 영향을 받는다고 가정해봅시다. 심지어 한 뉴런의 활성화가 이전 시간대의 자기 자신의 활성화에 의해 부분적으로 결정될 수도 있습니다. 이는 순방향 신경망에서는 확실히 일어나지 않는 일입니다. 또는 은닉 뉴런이나 출력 뉴런의 활성화가 신경망 현재 입력뿐만 아니라 이전의 입력에도 영향을 받을 수 있습니다.
이러한 종류의 시간 변화적 동작을 가진 신경망을 순환 신경망(RNNs)이라고 합니다. 지난 섹션에서 비공식적으로 설명한 순환 신경망을 수학적으로 형식화하는 방법은 여러 가지가 있습니다. RNN에 대한 위키피디아 페이지를 보면 이러한 수학적 모델의 일부를 엿볼 수 있습니다. 십여가지가 넘는 다양한 모델들에 대해서 위키피디아에서는 다루고 있습니다. 하지만 수학적 세부 사항은 차지하고, 넓은 의미에서 RNN은 시간에 따른 동적인 변화라는 개념이 포함된 신경망입니다. 따라서 당연하게도, 시간에 따라 변하는 데이터나 프로세스를 분석하는 데 특히 유용합니다. 예를 들어, 음성이나 자연어와 같은 문제에서 이러한 데이터와 프로세스가 자연스럽게 필요합니다.
현재 RNN이 사용되는 한 가지 방법은 신경망을 "튜링 머신(Turning machine)"이나 기존의 프로그래밍 언어와 같은 전통적인 알고리즘적 사고방식과 더 밀접하게 연결하는 것입니다. 2014년 논문에서는 (매우, 매우 간단한) 파이선 프로그램의 문자별 설명을 입력으로 받아 출력을 예측할 수 있는 RNN을 개발했습니다. 간단히 말해, 이 신경망은 특정 파이선 프로그램을 "이해하는 법"을 배우는 것입니다. 또 다른 논문, 역시 2014년에 발표된 것인데, RNN을 출발점으로 삼아 "신경 뉴링 머신(neural Turning machine, NTM)"이라고 부르는 것을 개발했습니다. 이는 전체 구조가 경사 하강법을 이용해 훈련될 수 있는 범용 컴퓨터입니다. 이들은 NTM을 훈련시켜 정렬(sorting)이나 복사(copying)와 같은 몇 가지 간단한 문제에 대한 알고리즘을 추록하도록 했습니다.
현시점에서 이들은 극도로 간단한 장난감 모델에 불과합니다. print(398345+42598) 와 같은 파이선 프로그램을 실행하도록 배우는 것이 신경망을 완전한 파이선 인터프리터로 만든느 것은 아닙니다. 이러한 아이디어를 얼마나 더 발전시킬 수 있을지는 불분명합니다. 그럼에도 불구하고 그 결과는 흥미롭습니다. 역사적으로 신경망은 기존의 알고리즘적 접근 방식이 어려움을 겪는 패턴 인식 문제에서 좋은 성과를 냈습니다. 반대로 기존의 알고리즘적 접근 방식은 신경망이 잘하지 못하는 문제를 해결하는데 능숙합니다. 오늘날 웹 서버나 데이터베이스 프로그램을 신경망으로 구현하는 사람은 아무도 없습니다. 신경망과 기존 알고리즘 접근 방식의 강점을 통합하는 통합 모델을 개발하는 것은 매우 중요합니다. RNN과 RNN에서 영감을 얻은 아이디어들이 이를 돕는데 기여할 수 있습니다.
RNN은 최근 몇 년 동안 다른 많은 문제들을 해결하는 데도 사용되었습니다. 특히 음성 인식에서 유용성이 입증되었습니다. RNN 기반 접근법은 예를 들어 음소 인식 정확도에서 기록을 세우기도 했습니다. 또한 사람들이 말할 때 사용하는 언어에 대한 개선된 모델을 개발하는 데에도 사용되었습니다. 더 나은 언어 모델은 그렇지 않으면 똑같이 들리는 발화를 구별하는 데 도움이 됩니다. 예를 들어 좋은 언어 모델은 "to infinity and beyond"가 "two infinity and beyond"보다 훠린 더 가능성이 높다는 것을 알려줄 것입니다. 두 구문이 똑같이 들리더라도 말이죠. RNN은 툭정 언어 벤치마크에서 새로운 기록을 세우기도 했습니다.
이러한 연구는 우연히도 RNN뿐만 아니라 모든 종류의 심층 신경망이 음성 인식에 광범위하게 사용되는 추세의 일부입니다. 예를 들어, 심층 신경망 기반 접근법은 대규모 어휘 연속 음성 인식에서 탁월한 결과를 보였습니다. 그리고 신층 신경망 기반의 또 다른 시스템은 구글 안드로이드 은영체제에 포함되기도 했습니다.
지금까지 RNN이 무엇을 할 수 있는지에 대해서 다루었지만 어떻게 작동하는지에 대해서는 많이 다루지 않았습니다. 순방향 신경망에서 사용되는 많은 아이디어들이 RNN에서도 사용될 수 있다는 것을 알게 되더라도 놀라지 않을 것입니다. 특히, 경사 하강법과 역전파를 간단하게 수정하여 RNN을 학습시킬 수도 있습니다. 정규화 기법부터 합성곱, 활성화 및 비용 함수에 이르기까지 순방향 신경망에서 사용되는 많은 아이디어들도 순환 신경망에서 유용합니다. 따라서 우리가 다룬 많은 기법들을 RNN에 맞춰서 적용할 수 있습니다.
심층 신뢰 신경망(Deep Belief Netwrok, DBN), 생성 모델(generative model) 및 볼츠만 머신(Bolzmann machine): 심층 학습에 대한 현대적 관심은 2006년에 심층 신뢰 신경망(Deep Belief Network, DBN)이라는 신경망 학습 방법을 설명하는 논문이 발표되면서 시작되었습니다. DBN은 몇 년 동안 영향력이 컸지만, 이후 순방향 신경망이나 순환 신경망과 같은 모델들이 유행하면서 인기가 시들해졌습니다. 그럼에도 불구하고 DBN은 흥미로운 여러가지 특징을 가지고 있습니다.
DBN이 흥비로운 한가지 이유는 생성 모델(generative model)이라고 불리는 것의 한 예이기 때문입니다. 우리가 사용해온 순방향 신경망에서는 입력 활성화가 일어나면, 이것이 신경망의 다음 계층에 있는 특징 뉴런들의 활성화에 영향을 미칩니다. DBN과 같은 생선 모델도 비슷한 방식으로 사용될 수 있지만 일부 특징 뉴런의 값을 지정한 다음 신경망을 "거꾸로 실행"하여 입력 활성화에 대한 값을 생성하는 것도 가능합니다. 좀 더 구체적으로 말하면, 손글씨 숫자 이미지로 훈련된 DBN은 (잠재적으로, 그리고 약간의 주의를 기울이면) 손글씨 숫자처럼 보이는 이미지를 생성하는데도 사용될 수 있습니다. 다시 말해, DBN이 어떤 의미에서는 글씨 쓰는 법을 배우는 것입니다. 이런 점에서 생성 모델은 인간의 뇌와 매우 유사합니다. 숫자를 읽을 수 있을 뿐만 아니라 쓸 수도 있기 때문입니다. 제프리 힌턴(Geoffrey Hinton)의 인상적인 표현을 빌리자면, "모양을 인식하려면, 먼저 이미지를 생성하는 법을 배워라"라고 할 수 있습니다.
DBN이 흥미로운 두 번째 이유는 비지도 및 준지도 학습을 수행할 수 있기 때문입니다. 예를 들어 이미지 데이터로 훈련할 때, DBN은 학습 이미지가 레이블이 없더라도 다른 이미지를 이해하는 데 유용한 특징들을 학습할 수 있습니다. 그리고 비지도 학습을 수행하는 능력은 근본적인 과학적 이유뿐만 아니라 충분히 잘 작동하게 만들 수 있다면 실용적인 응용 분야에서도 매우 흥비롭습니다.
이러한 매력적인 특정에도 불구하고 왜 DBN은 신층 학습 모델로서 인기가 시들해졌을까요? 부분적인 이유는 순방향 신경망이나 순환 신경망과 같은 모델들이 이미지나 음석 인식 벤치마크에서 획기적인 성과를 거두는 등 여러 가지 놀라운 결과를 달성했기 때문입니다. 현재 이 모델들에 많은 관심이 쏠리는 것은 당연하고 타당합니다. 그러나 안타까운 결과도 있습니다. 아이디어 시장은 종종 승자 독식 방식으로 작동하여 어떤 분야에서든 현재 유행하는 것에 거의 모든 관심이 쏠리는 경향이 있습니다. 비록 장기적으로 분명히 매우 흥비로운 아이디어라 하더라도 잠시 유행에서 벗어난 아이디어를 연구하는 것은 극도로 어려워질 수 있습니다. DBN과 다른 생성형 모델들이 현재 받고 있는 관심보다 더 많은 관심을 받을 자격이 있다고 생각합니다. 그리고 언젠가 DBN이나 관련 모델이 현재 유행하는 모델들을 능가할 수도 있습니다. DBN에 대한 입문자료로 다음 자료들을 참고하시길 바랍니다.
- DBN 개요
- 볼츠만 머신 훈련 가이드 (DBN 자체에 대한 내용은 아니지만, DBN의 핵심 구성요소인 제한된 볼츠만 머신(restricted Boltzmann machine)에 대한 유용한 정보가 많음)
"시스템을 설계하는 모든 조직은 ... 필연적으로 그 조직의 소통 구조를 복제한 구조를 가진 디자인을 만들어 낸다."
예를 들어 콘웨이의 법칙에 따르면 보잉 747 항공기의 디자인은 747이 설계될 당시 보잉과 계약업체들의 확장된 조직 구조를 반영합니다. 더 간단하고 구체적인 예로 복잡한 소프트웨어 애플리케이션을 만드는 기업을 생각해 봅시다. 만약 애플리케이션의 대시보드가 특정 기계 학습 알고리즘과 통합되어야 한다면, 대시보드를 만다는 사람은 당연히 그 기업의 기계학습 전문가와 대화해야합니다. 콘웨이 법칙은 이러한 관찰을 확대해서 표현한 것일 뿐입니다.
콘웨이의 법칙을 처음 들었을 때 사람들은 "그거 너무 진부하거 뻔한 거 아닌가요?" 또는 "그거 틀린 거 아닌가요?"라고 반응합니다. 먼저, 틀렸다는 반론부터 다루어보도록 하겠습니다. 이 반론의 예로 보잉의 회계 부서가 747 디자인에 어떻게 반영될까요? 청소 부서는요? 사내 마케팅 부서는요? 그 대답은 이 조직의 부서들은 747에 명시적으로 나타나지 않을 가능성이 높다는 것입니다. 따라서 우리는 콘웨이의 법칙을 명시적으로 설계 및 엔지니어링에 관련된 조직 부분에만 적용되는 것으로 이해해야 합니다.
그렇다면 다른 반론, 즉 진부하고 뻔하다는 반론은 어떨까요? 이 말도 맞을 수 있지만, 반드시 그렇지는 않습니다. 왜냐하면 조직들은 너무나 자주 콘웨이의 법칙을 무시하고 행동하기 때문입니다. 신제품을 만드는 팀은 종종 오래된 인력으로 부풀려지거나, 반대로 핵심적인 전문성을 가진 사람이 부족한 경우가 있습니다. 쓸모없고 복잡한 기능이 있는 모든 제품들을 생각해 보세요. 또는 명백한 주요 결함이 있는 모든 제품들을 생각해보세요. 두 가지 종류의 문제 모두, 좋은 제품을 만드는 데 필요했던 팀과 실제로 구성된 팀 사이의 불일치가 있을 때 종종 발생합니다. 콘웨이의 법칙은 뻔해 보일 수 있지만 사람들이 일상적으로 이를 무시하지 않는다는 뜻은 아닙니다.
콘웨이의 법칙은 우리가 구성 요소와 그것을 만드는 방법을 꽤 잘 이해하고 있는 시스템의 설계 및 엔지니어링에 적용됩니다. 하지만 인공지능 개발에는 직접적으로 적용할 수 없습니다. 왜나하면 인공지능은 아직 그런 문제가 아니기 때문입니다. 우리는 구성 요소가 무엇인지 모릅니다. 심지어 어떤 기본적인 질문을 해야하는지도 확신하지 못합니다. 다시 말해, 이 시점에서 인공지능은 엔지니어링 문제라기 보다는 과학의 문제에 가깝습니다. 제트 엔진이나 공기역학의 원리를 모르는 상태에서 747을 설계한다고 생각해보세요. 어떤 종류의 전문가를 고용해야 할지조차 모를 것입니다. 베르너 폰 브라운(Wernher von Braun)이 말했듯이, "기초 연구란 내가 무엇을 하고 있는지 모를 때 하는 것이다." 엔지니어링보다 과학에 가까운 문제에 적용되는 콘웨이의 법칙 버전이 있을까요?
이 질문에 대한 통찰력을 얻기 위해 의학의 역사를 생각해보도록 합시다. 초창기 의학은 갈레노스와 히포크라테스 같은 의사들이 신체 전체를 연구하던 영역이었습니다. 하지만 지식이 커지면서 사람들은 전문화할 수밖에 없었습니다. 우리는 질병의 세균설, 항체의 작동방식에 대한 이해, 또는 심장, 폐, 정맥, 동맥이 완전한 심혈관계를 형성한다는 이해와 같은 여러 심오하고 새로운 사실들을 발견했습니다. 이러한 깊은 통찰력은 역학, 면역학, 그리고 심혈관계 관련 분야들의 기초가 되었습니다. 이처럼 지식의 구조가 의학의 사회적 구조를 형성했습니다. 특히 면역학의 경우가 두드러집니다. 면역 시스템이 존재하고 연구할 가치가 있는 시스템이라는 것을 깨닫는 것은 매우 비범한 통찰입니다. 그래서 우리는 전문가, 학회, 심지어 상까지 있는 의학 분야 전체가 보이지 않을 뿐만 아니라 어쩌면 실체가 아닐 수도 있는 무언가를 중심으로 조직되어 있는 것을 보게 됩니다.
이것은 의학뿐만 아니라 물리학, 수학, 화학 등 여러 확립된 과학 분야에서 반복되어 온 흔한 패턴입니다. 과학 분야는 몇 가지 깊은 아이디어만 가진 단일체로 시작됩니다. 초기 전문가들은 그 모든 아이디어를 마스터할 수 있습니다. 그러나 시간이 지나면서 그 단일체적 특성은 변합니다. 한 사람이 진정으로 마스터하기에는 너무 많은 심오하고 새로운 아이디어들을 발견하게 됩니다. 그 결과, 분야의 사회적 구조가 재조직되어 그 아이디어들을 중심으로 분화됩니다. 단일체 대신, 우리는 분야 속의 분야 속의 분야라는 복잡하고 재귀적이며 자기 참조적인 사회적 구조를 가지고 되며, 그 조직은 우리의 가장 깊은 통찰 사이의 연결을 반영합니다. 이처럼 지식의 구조가 과학의 사회적 조직을 형성합니다. 그러나 그 사회적 형태는 다시 우리가 무엇을 발견할 수 있는지를 제약하고 결정하는 데 도움이 됩니다. 이것이 콘웨이 법칙에 대한 과학적 비유입니다.
그렇다면 이것이 심층 학습이나 인공지능과 무슨 관련이 있을까요?
인공지능의 초창기부터 한쪽에서는 "이것이 그렇게 어렵지 않을 겁니다. 우리에게는 초특급 무기가 있으니까요"라고 주장하고, 다른 한쪽에서는 "초특급 무기만으로 충분하지 않을 겁니다."라고 반박하는 논쟁이 있었습니다. 심층 학습은 이러한 논쟁에서 가장 최신의 초특급 무기입니다. 초기 버전의 논쟁에서는 논리, 프롤로그, 전문가 시스템 등 그 시대의 가장 강력한 기술이 사용되었습니다. 이러한 논쟁의 문제는 주어진 초특급 무기가 얼마나 강력한지 제대로 말해줄 수 있는 방법이 없다는 것입니다. 물론 우리는 심층 학습이 극도로 어려운 문제들을 해결할 수 있다는 증거를 검토하는데 적지 않은 노력을 들였습니다. 확실히 매우 흥미롭고 유망해 보입니다. 하지만 프롤로그, 유리스코, 전문가 시스템 같은 기술들도 그 당시에는 마찬가지로 유망해 보였습니다. 따라서 단순히 어떤 아이디어들이 매우 유망해 보인다는 사실만으로는 큰 의미가 없습니다. 어떻게 심층 학습이 이러한 이전 아이디어들과 진정으로 다른지 알 수 있을까요? 아이디어의 집합이 얼마나 강력하고 유망한지 측정하는 방법이 있을까요? 콘웨이 법칙은 거칠과 경험적인 대리 지표로서, 그 아이디어와 관련된 사회적 구조의 복잡성을 평가할 수 있다고 주장합니다.
그래서 두 가지 질문을 던져봐야 합니다. 첫째, 사회적 복잡성이라는 이 척도에 따르면 심층 학습과 관련된 아이디어의 집합은 얼마나 강력할까요? 둘째, 범용 인공지능을 구축하기 위하여 얼마나 강력한 이론이 필요할까요?
첫 번째 질문에 대해: 오늘날 심층 학습을 보면 흥미롭고 매우 빠르게 발전하고 있지만 여전히 상대적으로 단일체적인 분야입니다. 몇 가지 깊은 아이디어와 몇 개의 주요 학회가 있으며 이들 학회 간에는 상당한 중복이 있습니다. 그리고 확률적 경사 하강법을 사용하여 비용 함수를 최적화하는 동일한 기본 아이디어 세트를 활용하는 논문들이 계속해서 나오고 있습니다. 이 아디어들이 매우 성공적이라는 것은 놀라운 일입니다. 하지만 우리가 아직 보지 못하는 것은 각자의 깊은 아이디어 세트를 탐구하며 심층 학습을 여러 방향으로 밀고 나가는 잘 발달된 하위 분야들입니다. 따라서 사회적 복잡성이라는 척도에 따르면 심층 학습은 말장난처럼 들릴지 모르지만, 여전히 얕은 분야입니다. 한 사람이 이 분야의 가장 깊은 아이디어 대부분을 마스터하는 것이 여전히 가능합니다.
두 번째 질문에 대해: 인공지능을 얻기 위해 얼마나 복잡하고 강력한 아이디어 세트가 필요할까요? 물론, 이 질문에 답은 아무도 확실히 모른다는 것입니다. 이 질문에 대한 기존 증거들을 검토한 결과를 부록에 담았습니다. 꽤 낙관적으로 본다하더라도 인공지능을 구축하기 위해서는 매우, 매우 많은 깊은 아이디어가 필요할 것이라고 판단됩니다. 따라서 콘웨이의 법칙은 그러한 지점에 도달하기 위해서는 우리의 가장 깊은 통찰력 속의 구조를 반영하는 복잡하고 놀라운 구조를 가진 많은 상호 연관된 학문 분야의 출현을 필연적으로 보게 될 것이라고 시사합니다. 우리는 신경망과 심층 학습의 사용에 아직 이 풍부한 사회적 구조를 보지 못하고 있습니다. 따라서 심층 학습을 사용하여 범용 인공지능을 개발하기까지는 적어도 수십 년이 더 걸릴 것이라 믿습니다.
여기서 우리는 잠정적이고, 다소 뻔해 보이며, 불확실한 결론을 내리기 위해 많은 노력을 들여 논증을 구성했습니다. 이는 획실성을 갈망하는 사람들을 좌절시킬 수도 있습니다. 인터넷에는 비약한 추론과 존재하지 않는 증거들을 바탕으로 인공지능에 대해 매우 단정적이고 강한 주장을 펴는 많은 사람들을 볼 수 있습니다. 이에 대한 솔직한 의견은 이렇습니다. 아직 말하기에는 너무 이르다는 것입니다. 오래된 농담처럼, 과학자에게 어떤 발견이 얼마나 남았는지 물었을 때 "10년"(또는 그 이상)이라고 대답하면, 그들이 의미하는 바는 "전혀 모른다"입니다. 인공지능은 통제된 핵융합과 같은 몇몇 다른 기술처럼 60년 이상 동안 "10년 후"에 머물러 있었습니다. 반면에 우리가 심층 학습에서 확실한 것은 아직 한계가 발견되지 않은 강력한 기술이며, 해결해야할 근본적인 문제도 많다는 것입니다. 이것이야 말로 흥미진진한 창조적 기회입니다.

댓글 없음:
댓글 쓰기